Dans mon dernier article je vous parlais de jubeatools, un convertisseur entre plusieurs formats de partitions jubeat que je code sur mon temps libre. Récemment j'ai recommencé à travailler dessus, remotivé par l'appel à l'aide de quelqu'un tombé sur un bug en essayant de l'utiliser.
Cet article ne parle pas du bug de cette personne (qui n'avait rien de très spécial) mais d'un autre bug sur lequel je viens de tomber un peu au hasard (encore une fois grâce à hypothesis).
#memo
Comme teasé à la fin de mon article précédent, jubeatools ne gère pas uniquement le format que j'y avais décrit. L'article présentait #memo2, le format plus moderne mais aussi le moins bordélique des 4 formats de la "famille" jubeat analyser. Il existe aussi #memo, #memo1, et un format sans tag que la documentation appelle avec un nom du genre "le format mono-colonne" ("1列形式" dans le texte).
Le bug qui nous intéresse touchait le code qui s'occupe du format #memo, un hybride chelou entre le mono-colonne et #memo2.
#memo ressemble visuellement beaucoup à #memo2, mais avec une bizarrerie majeure : la partie timing se comporte différemment. En #memo chaque symbole de la partie timing représente une durée fixée à 1/4 de battement. Si votre partition n'a pas besoin de représenter un autre rythme, le format reste visuellement le même qu'en #memo2 :
□①①□ |①-②③|
□□□□ |④⑤⑥⑦|
③⑦□④
②⑤⑥②
⑭⑪⑫⑭
□⑨⑩□
□□⑧□ |⑧⑨⑩⑪|
⑬□□⑬ |⑫⑬-⑭|
⑭⑪⑫⑭ |-①②③|
⑦⑨⑩⑧ |④⑤⑥⑦|
⑤③④⑥ |⑧⑨⑩⑪|
⑬①②⑬ |⑫⑬-⑭|
On reconnais du format #memo2 les deux colonnes, position à gauche et timeline à droite, avec les fameux nombres cerclés pour représenter des notes.
Jusqu'ici rien d'étonnant.
Par contre, si vous devez représenter des rythmes en 1/3 de battements, alias un triolet pour ceux qui veulent se la péter et / ou qui ont fait du solfège, dans ce cas ça se complique.
Là où en #memo2 on peux tout simplement mettre des barres de longueur 3 comme ça :
34
④⑤⑥口 |①-②|
口⑦⑧⑨ |③--|
③口口③ |④⑤⑥|
②①①② |⑦⑧⑨|
35
④⑤⑥口 |①-②|
口⑧口⑦ |③--|
③口口③ |④⑤⑥|
②①①② |⑦-⑧|
En #memo on ne peux pas, du coup il va falloir faire ça :
*①:0.000
*③:0.667
*④:1.000
*⑦:2.000
*⑧:2.333
*⑨:2.667
*⑩:3.000
*⑪:3.333
*⑫:3.667
⑦⑧⑨□ |----|
□⑫⑪⑩ |----|
④□□④ |----|
③①①③ |----|
⑦⑧⑨□ |----|
□⑫□⑩ |----|
④□□③ |----|
③①①④ |----|
Les lignes au début en forme de *⑫:3.667 sont des définitions de symboles, ici par exemple ça veux dire que le symbole ⑫ correspond à une note qui arrive au temps 3.667 (≈ 3 + 2/3 battements)
(temps symbolique, dans le sens compté en battements et pas en secondes)
(temps relatif au début du bloc, donc ici aux deux tiers de la quatrième barre du bloc, peu importe le bloc)
Il n'est donc plus obligatoire de mettre un symbole dans la timeline pour pouvoir l'utiliser dans la partie position. À la place on peut comme ici donner le temps correspondant au symbole à l'avance, souvent juste avant de l'utiliser.
Par contre remarquez qu'il faut quand même garder des |----| vides à droite. Ça c'est parce que si on ne les met pas, les parties position sans aucun |----| à leur droite vont être comprises comme la suite de la définition du bloc précédent, mais juste étalée en plusieurs fois. Le temps n'avance pas si il n'y a pas de |----|.
Enfin bref, vous vous en doutez, une joie à parser et à interpréter.
Bon test, bon bug
Heureusement ce format (comme tous les autres pour l'instant), a un test unitaire associé, et en plus pas n’importe lequel, un test écrit avec hypothesis !
Dans jubeatools j'ai une chance incroyable : 99% du code utile suit le motif encodeur+décodeur, ce qui permet de faire des très bon tests avec hypothesis. On est en présence de ce motif parce que pour chaque format que jubeatools gère il y a :
- une représentation A (ici le format texte
#memo) - une représentation B (mon objet python qui contient les notes de la partition)
- un couple de fonctions encodeur+décodeur pour passer de l'une à l'autre
Dès que vous repérez ce motif dans votre code, hypothesis va vous aider mais TELLEMENT FORT. Vous n’êtes pas prêts. Ce motif de test marche tellement bien que c'est même l'exemple choisi pour montrer comment hypothesis c'est le feu dans la partie "Quick Start" de la doc. A mon avis c'est aussi un peu dans le but de vous faire oublier un instant que le gros sujet avec cette lib ça reste de trouver d'autres motifs de test où elle peut vraiment effectivement servir à quelque chose.
Tout ça pour dire que, pour pouvoir tester mon code avec hypothesis, je dois écrire un décodeur de fichier #memo en objet python mais aussi un encodeur d'objets python en fichier #memo
Et c'est grâce à ces deux choses que j'ai pu trouver mon bug de l'espace.
Un indice pour commencer
Défi bonus : trouver le bug avant la prochaine partie
Le code qui doit écrire un fichier #memo à partir de l'information "pure" (quelle note est où et quand) doit donc gérer ce fameux cas où une note ne suit pas une division en quart de battement, et doit en conséquence créer des définitions de symboles.
Pour simplifier le code j'avais décidé que mes définitions n'écraseraient pas de définition précédente. Une redéfinition comme ça, ça peux arriver dans un fichier #memo sauvage observé dans son habitat naturel. Un peu comme dans l'exemple plus haut qui montre qu'il est possible de redéfinir le temps associé aux nombres cerclés. Je ne voulais pas devoir gérer ça dans le code d'écriture vu qu'a priori on a pas besoin de faire des redéfinitions pour écrire un fichier correct.
Dans mon code donc, chaque nouvelle définition utilise un nouveau symbole, choisi dans l'ordre dans une grosse liste de symboles définie par ce bout de code
# I put a FUCKTON of extra characters just in case some insane chart uses
# loads of unusual beat divisions
DEFAULT_EXTRA_SYMBOLS = (
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん"
"アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲン"
)
Notez le commentaire plein d'espoir.
On a donc l'alphabet pleine chasse en majuscule puis en minuscule, les hiragana et enfin les katakana. Soit au total 144 symboles supplémentaires, je m'étais dit que ça irai.
Je suis d'accord qu'en général dans du code, ça pue l'amateurisme de choisir à l'avance un stock fixe de ressources en espérant que ça soit assez, alors que la consommation se fait à l’exécution et n'est pas vraiment prévisible. Mais le plus savoureux c'est que le bug que je vous présente ne se produit même pas directement à cause de ça. Enfin ... pas loin ... mais le problème n'est pas qu'on épuise la liste de symboles supplémentaires.
Bref, une fois que vous savez ça, vous êtes prêt à comprendre le bug, certains d'entre vous l'ont même sûrement déjà deviné.
Rhoo ça plante
Un beau jour, mes tests unitaires semblent tourner en boucle sur le test du format #memo, je me demande bien ce que ça peut être, d'habitude ça prend pas plus d'une seconde. J'ai pas vraiment touché la logique de lecture / écriture, mais bon je reviens d'une grosse session de rangement et nettoyage du code donc je me dis pourquoi pas.
La seule fois où hypothesis a vraiment planté comme ça, c'était parce qu'il avait trouvé une boucle infinie dans mon code. Pour vérifier si c'est pas ça le problème je coupe pendant que ça a l'air de boucler et je regarde où en était l’exécution ... non bah ça a pas l'air d'être une boucle infinie, je tombe sur un endroit différent à chaque fois.
Je décide de laisser tourner pour voir, au bout d'un bon moment le test échoue, et hypothesis me dit "tiens j'ai trouvé un cas d'erreur que j'arrive pas à simplifier !" :
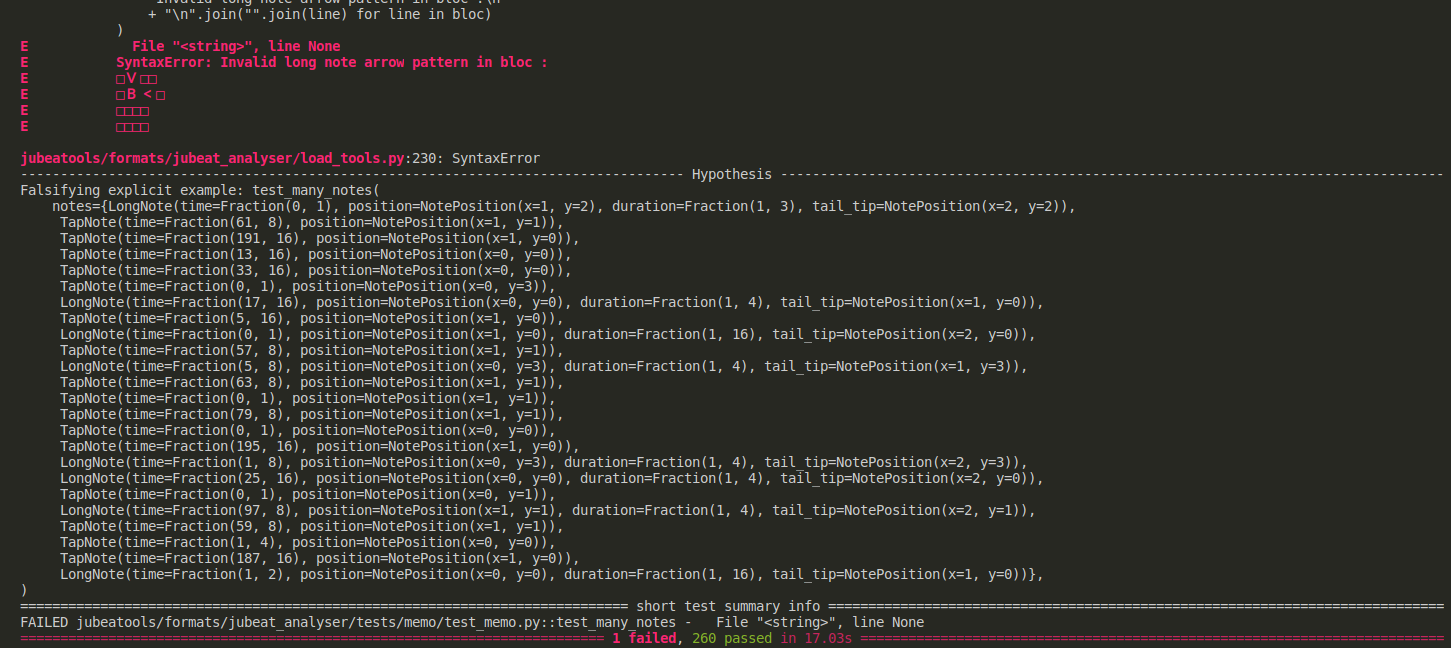
En effet c'est pas simple, 24 objets comme cas minimal pour un bug ça a effectivement l'air du genre de bug qu'on remarque pas tout de suite
Visiblement mon code n'est pas content de tomber sur un bloc comme ça :
□∨□□
□B<□
□□□□
□□□□
avec deux flèches qui pointent sur le B en même temps. En effet c'est pas un motif de flèches valide ... comme on l'a vu dans le post précédent ...
J'essaye de simplifier moi même le cas de bug, en me disant que ça doit être une collision dans l'écriture des notes longues, mais non rien, si je ne laisse que les notes longues y'a plus le problème ...
Encore sur la même piste je me demande si c'est pas le fait qu'il y ai beaucoup de notes avec des temps chelou et toutes sur la position du B qui a eu raison du bout de code qui s'occupe de séparer les définitions de bloc qui se chevauchent ... mais non, non plus ... quand je ne laisse que les notes en position (1,1), le bug disparaît.
Alors, une idée ?
Spoiler
Je me souvient alors de la manière dont est implémenté le test :
Il génère des objets python qui représente les notes, les passe dans l'encodeur, puis passe sa sortie dans le décodeur, puis vérifie qu'on retombe sur les mêmes objets. En quelque sorte on s'assure que la représentation en #memo conserve correctement l'information, que les notes "survivent" à un passage par la représentation textuelle.
Du coup pour le cas du bug ça donne quoi cette représentation textuelle ?
// Converted using jubeatools 0.1.1
// https://github.com/Stepland/jubeatools
t=120
m="."
o=0
#lev=0
#dif=3
#jacket="."
#holdbyarrow=1
#memo
*A:0.062500
*B:0.125000
*C:0.312500
*D:0.333333
*E:0.375000
*F:0.562500
*G:0.625000
*H:0.812500
*I:0.875000
*J:1.062500
*K:1.312500
*L:1.562500
*M:1.812500
*N:2.062500
①①<□ |①②③−|
①①□□
□①<□
①□□□
②A□□
□□□□
□□□□
B―<□
□C□□
□□□□
□D□□
E□□□
③<□□
□□□□
□□□□
□□□□
F□□□
□□□□
□□□□
G<□□
H□□□
□□□□
□□□□
I□□□
J<□□
□□□□ |−−−−|
□□□□
□□□□
K□□□
□□□□
□□□□
□□□□
L―<□
□□□□
□□□□
□□□□
M□□□
□□□□
□□□□
□□□□
N□□□
□□□□
□□□□ |−−−−|
□□□□ |−−−−|
*O:3.125000
*P:3.375000
*Q:3.625000
*R:3.875000
□□□□ |−−−−|
□□□□ |−−−−|
□□□□ |−−−−|
□□□□
□□□□
□O□□
□□□□
□□□□ |−−−−|
□□□□
□P□□
□□□□
□□□□
□□□□
□Q□□
□□□□
□□□□
□□□□
□R□□
□□□□
□□□□
*S:1.875000
*T:3.687500
*U:3.937500
□□□□ |−−−−|
□S□□ |−−−−|
□□□□ |−−−−|
□□□□
□T□□
□□□□
□□□□
□□□□ |−−−−|
□U□□
□□□□
□□□□
□□□□
*V:0.187500
□V□□ |−−−−|
□B<□
□□□□
□□□□
□□□□
□E□□
□□□□
□□□□
□□□□
□□□□ |−−−−|
□□□□ |−−−−|
□□□□ |−−−−|
Bah wow en effet c'est long, c'est pas un exemple simple du tout, mais laisse moi regarder deux secondes ...
Ah bah cool ! On retrouve notre bloc avec le B et les deux flèches :
*V:0.187500
□V□□ |−−−−|
□B<□
□□□□
□□□□
□□□□
□E□□
□□□□
□□□□
□□□□
□□□□ |−−−−|
□□□□ |−−−−|
□□□□ |−−−−|
Trop chelou ... on définit le symbole V et après on l'utilise même pas ...
attends ...
*V:0.187500
□V□□ |−−−−|
□B<□
□□□□
□□□□
ATTENDS ...
*V:0.187500
□V□□ |−−−−|
□B<□
□□□□
□□□□
SI, SI, ON L'UTILISE
refais voir la liste des symboles supplémentaires ?
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん
アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲン
et montre vite fait la liste des symboles de flèches acceptés ?
- "V" # U+0056 : LATIN CAPITAL LETTER V
- "v" # U+0076 : LATIN SMALL LETTER V
- "Ⅴ" # U+2164 : ROMAN NUMERAL FIVE
- "ⅴ" # U+2174 : SMALL ROMAN NUMERAL FIVE
- "∨" # U+2228 : LOGICAL OR
- "V" # U+FF36 : FULLWIDTH LATIN CAPITAL LETTER V
- "v" # U+FF56 : FULLWIDTH LATIN SMALL LETTER V
woooooooow, ok
En gros
Il y avait une collision entre les symboles supplémentaires choisi par le dumper et les symboles acceptées comme bouts de flèches par le parser. Le dumper a besoin d'utiliser tellement de symboles supplémentaires qu'on arrive jusqu'au V. Ce même V est confondu par le parser avec une pointe de flèche de note longue.
Je vous laisse admirer le fait que l'erreur précise trouvée par le test ne se révèle que si :
- le groupe de note que vous voulez écrire utilise tellement de définitions qu'on arrive jusqu'à
V - ET qu'il faut écrire le
Vau dessus d'une autre note (dans la partie position) - ET que cette note en dessous du
Vest également une note longue - ET que la pointe de flèche de cette note longue n'est pas en collision avec la position du
V
Dans les faits le test aurait pu relever des variantes de l'erreur observée juste en vérifiant la première condition.
Mais quand même ... wow ... vive le property-based testing, mangez-en, et mettez des gros gros chiffres dans les réglages