
Quand sam & max disent que l'encodage, c'est compliqué, je pensais pas en arriver là où ce nouveau bug dans jubeatools m'a amené.
Pour ceux qui viennent d'arriver, jubeatools est un outil en ligne de commande que je développe sur mon temps libre. Il sert à convertir entre différents formats de fichier-partition pour un jeu de rythme qui s'appelle jubeat. Y'a plein de vidéo de gens qui y jouent sur youtube si vous voulez voir à quoi le jeu ressemble.
La difficulté principale dans jubeatools c'est la gestion d'une famille de formats en particulier : les formats "jubeat analyser". Je les appelle comme ça parce que ce sont ceux supportés par le logiciel du même nom. cf. mon premier article si vous voulez plus de détails.
Le truc important pour cet article c'est de savoir que D'HABITUDE, les fichiers qui suivent ces formats sont des fichiers texte correctement encodés en ✌️Shift-JIS✌️.
Notez bien le "D'HABITUDE" et les guillemets avec les doigts autour de ✌️Shift-JIS✌️
Voila donc qu'un beau jour ...
Quelqu'un me contacte pour me dire qu'il n'arrive pas à convertir son fichier avec jubeatools. Pourtant ce fichier fonctionne avec jubeat analyser ...
J'y jette un coup d’œil :
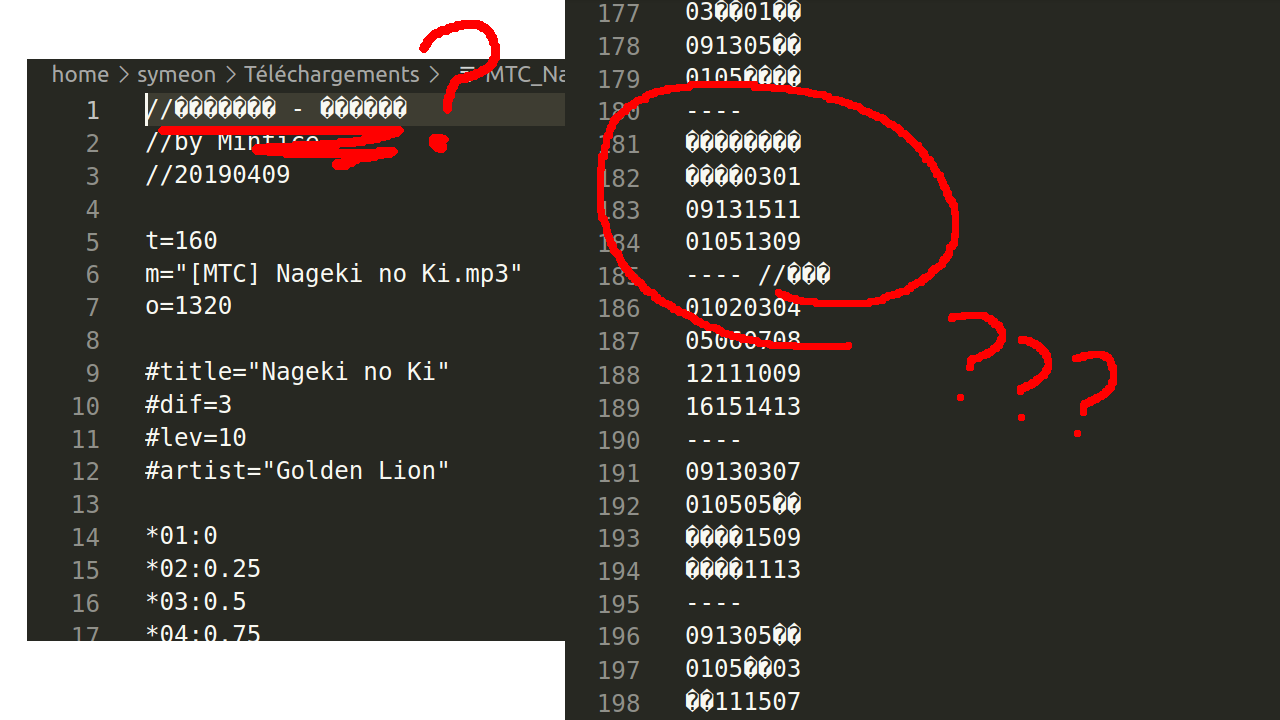
À cette étape là la présence de � à l'affichage ne m'inquiète pas plus que ça. C'est ptet juste que mon éditeur texte n'a pas détecté l'encodage tout seul. voyons ce que ça donne si je lui indique que c'est du ✌️Shift-JIS✌️ ...
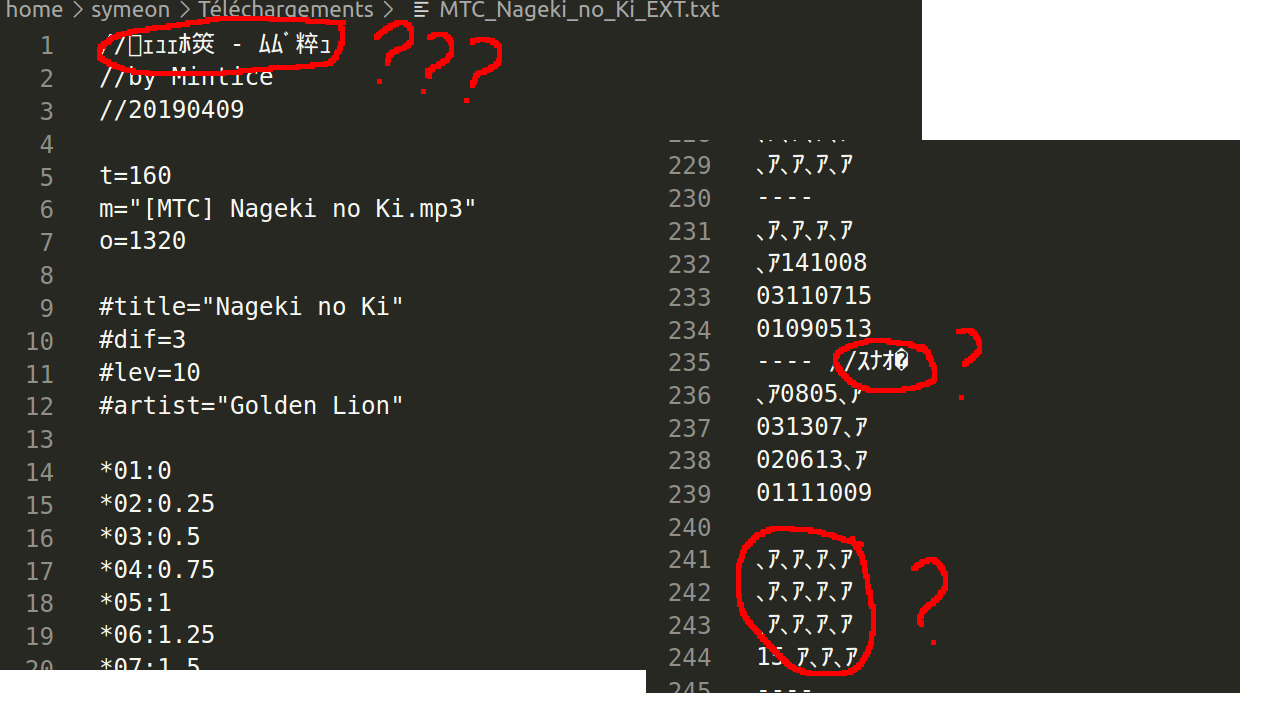
Là c'est étrange :
- le commentaire au début n'a pas l'air d'avoir été mieux décodé
- la partition est pleine de
、ア: ça sent le mojibake - pire, il reste même encore un � !
Pour ceux qui ne connaîtrait pas le �, c'est une manière courante de représenter qu'à cet endroit dans le fichier, la séquence d'octets n'a pas pu être comprise comme du texte valide selon l'encodage choisi. Ici je suis donc 99% sûr de ne pas avoir utilisé le bon encodage.
En vrai il n'y a pas eu mystère sur l'encodage, la personne qui m'a contacté a directement indiqué que le fichier était en fait encodé en EUC-KR, un encodage pour le Coréen.
Et en effet quand on le lit en sachant ça, c'est mieux :
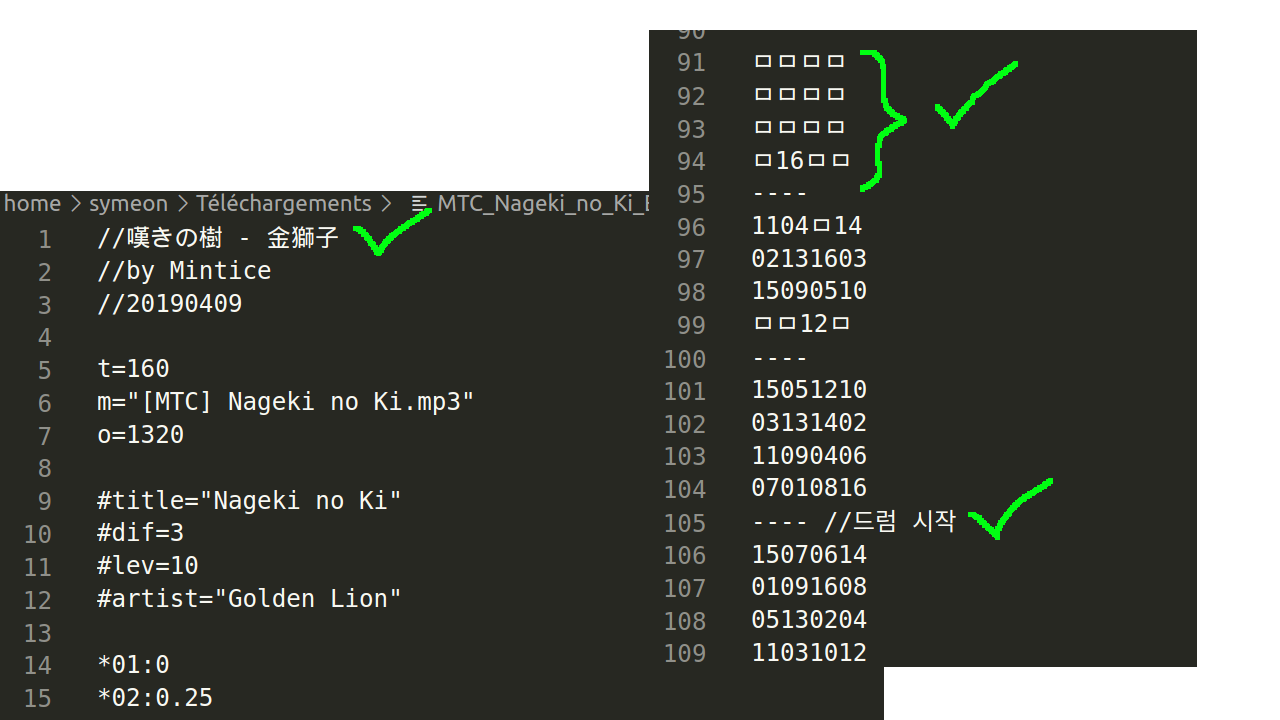
Mais ...
Alors comment ça se fait que ce fichier fonctionne correctement avec jubeat analyser ?
Le peu de documentation qui existe dit pourtant clairement que les fichiers doivent être en ✌️Shift-JIS✌️ pour être compris correctement ...
Bah tant pis, à ce moment là je commence déjà à évaluer les dégâts, et à me faire un plan d'attaque pour la manière dont je vais devoir demander à l'utilisateur de me passer l'encodage qu'il veux que j'utilise pour son fichier, sans parler des kilomètres de code que je vais devoir modifier pour passer correctement ce paramètre dans toute la chaîne de traitement ...
Quand soudain !
La personne m'envoie un deuxième fichier qui ne marche pas non plus, et dedans il y a ce qui mérite sans doute le prix de la plus belle bidouille multi-encodage que j'ai jamais vue ...
La personne m'explique que l'auteur original de cette partition a essayé de mettre des notes longues dedans.
Pour rappel, dans les formats de la famille jubeat analyser, les notes longues sont représentées visuellement, avec des flèches pour rappeler la forme qu'elles ont dans le jeu :
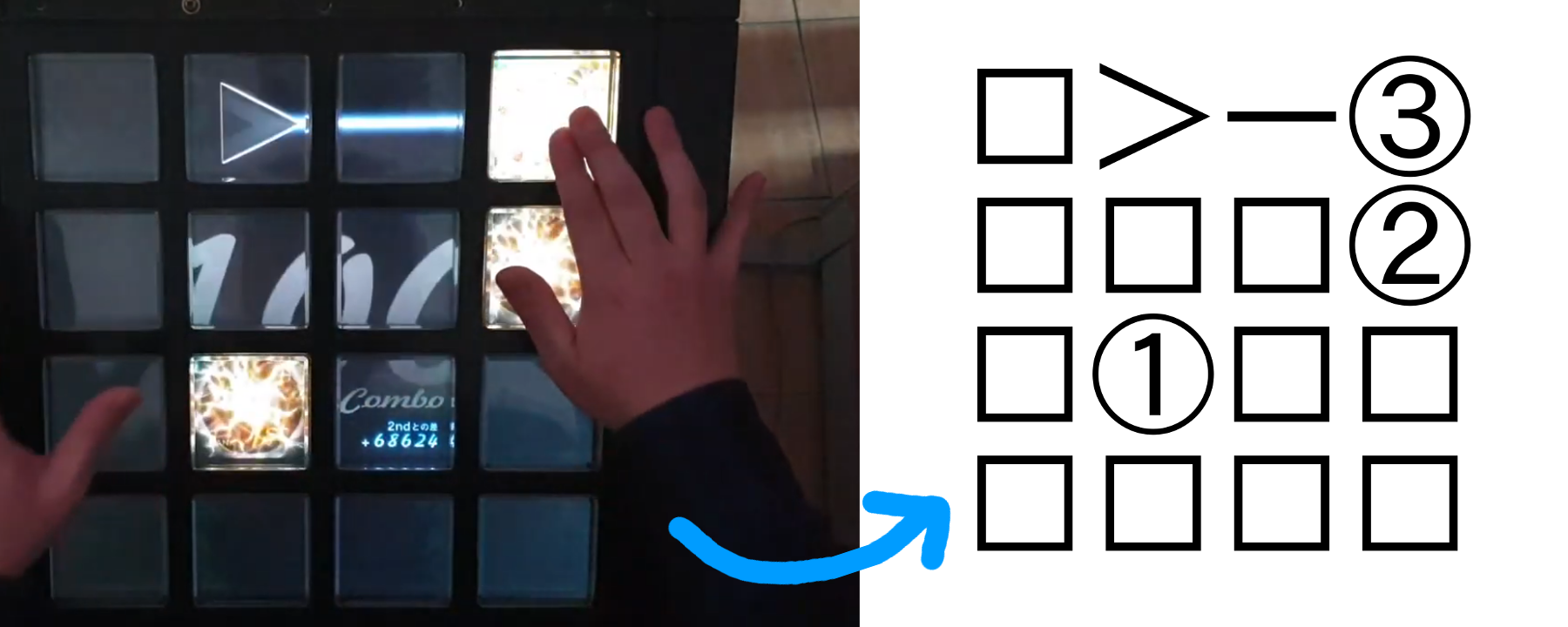
J'ouvre le deuxième fichier en m'attendant à trouver des > des < des ∨ et des ∧ un peu partout, et là surprise ! Si on lit le fichier en EUC-KR ... y'en a pas !
Par contre un commentaire au début indique ce qui est utilisé à la place
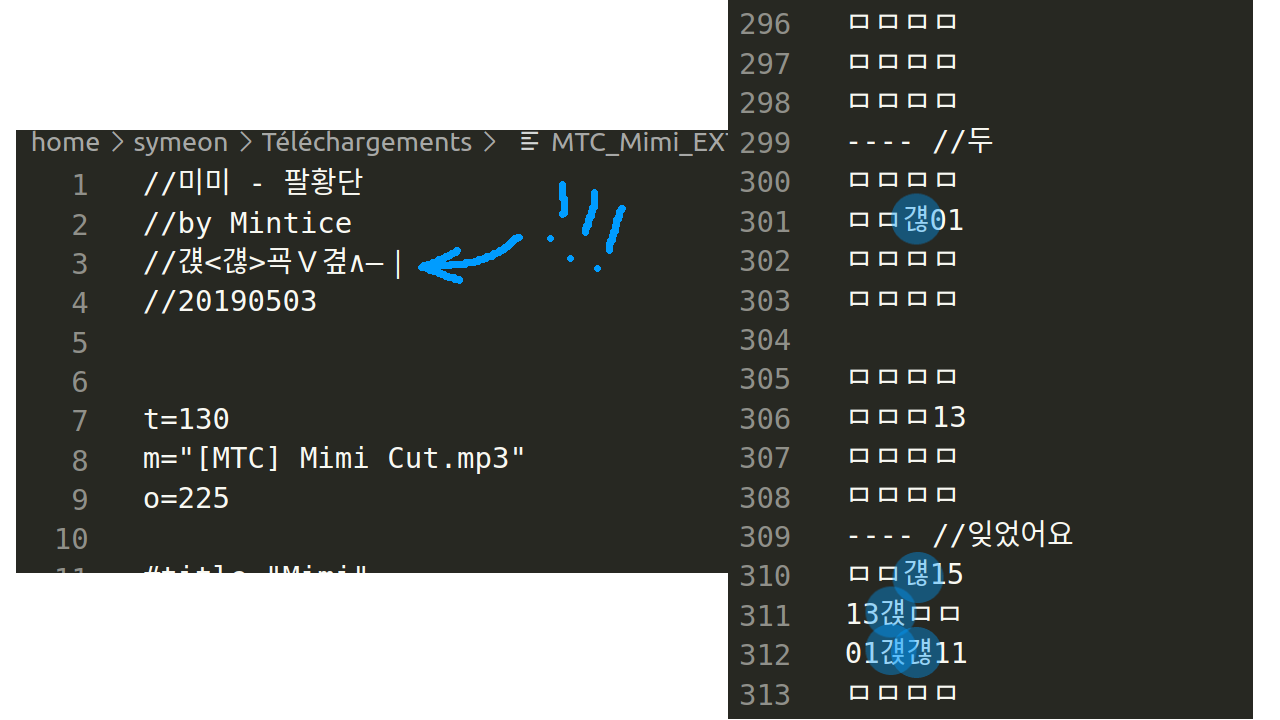
Mais ... mais ...
Pourquoi ça marche d'utiliser ces caractères là à la place des flèches en EUC-KR ? C'est pas du tout le même caractère ! Comment fait jubeat analyser pour comprendre que ces trucs sont des flèches ?
C'est là que je réalise : en fait jubeat analyser s'en fout complètement de l'encodage et manipule tout au niveau octets, sans rien décoder.
Quand la doc de jubeat analyser dit qu'il faut que les fichiers soient en ✌️Shift-JIS✌️, en fait il ne faut pas le comprendre au sens strict qui serait :
Le fichier doit pouvoir être entièrement décodé comme étant du ✌️Shift-JIS✌️ valide
Mais plutôt sans ce sens :
Ton encodage je m'en bat les couilles, mais si jamais je te demande d'écrire un symbole particulier dans ton fichier, il faut que la suite d'octets utilisée pour ce symbole soit la même qu'en ✌️Shift-JIS✌️
Du coup si on revient à mon bug, en fait à aucun moment jubeat analyser n'essaye de deviner l'encodage. En fait depuis le début il manipule tout comme une suite d'octets "brute" (comme c'est souvent le cas avec les langages de prog. qui vous font croire que octets==texte), et tant qu'il retrouve les octets qui lui conviennent aux endroit où il s'y attend y'a pas de problème.
Dans ce deuxième fichier, on est en fait face à de la rétro-ingénierie de mojibake faite maison, comme la faisait ma grand-mère.
L'auteur du fichier à trouvé à la main les caractères coréens qui vont s'encoder en EUC-KR de la même manière que les symboles de flèches en ✌️Shift-JIS✌️, autrement dit les caractères pour lesquels la suite d'octets sera la même.
Démontrons ça avec un petit tour de passe-passe numérique :
Je prend le caractère "걚" (qui d'après le commentaire en haut du fichier est utilisé à la place de ">")
>>> c = "걚"
Je l'encode en EUC-KR
>>> c.encode("euc-kr")
b'\xa4\xd4\xa4\xa1\xa4\xc2\xa4\xa6'
On obtient la suite d'octets
A4, D4, A4, A1, A4, C2, A4, A6
Ou encore en décimal :
164, 212, 164, 161, 164, 194, 164, 166
je prends ces octets et je fais "comme" jubeat analyser, j'essaye de les lire comme si c'était du ✌️Shift-JIS✌️
>>> c.encode("euc-kr").decode("shift-jis-2004")
'、ヤ、。、ツ、ヲ'
Heu ... attends on est pas censé trouver un truc genre ">" là ? wat ?
Pour aller plus au fond du fun, depuis le début je vous parle de EUC-KR, mais en fait j'ai remarqué au moment d'écrire ce passage que le fichier était dans ENCORE un autre encodage. Je me suis gouré parce que mon éditeur texte est VSCode, par Microsoft. Et quand on demande à Microsoft du EUC-KR, il va en fait, sans rien vous dire, y ajouter son extension kebab maison à la bien, qui pour python s'appelle "cp949" et pas "euc-kr".
Même genre de problème que pour ✌️Shift-JIS✌️ : Par la force des choses, Microsoft a imposé ses extensions non standard à un système qui avait déjà un nom, ce qui fait que ce que Microsoft appelle ✌️EUC-KR✌️ n'est pas ce que Wikipédia appelle EUC-KR.
Ça a l'effet secondaire absolument non-prémédité et complètement involontaire que 95% des gens pensent maintenant que l'extension propriétaire de Microsoft c'est le standard.
Bref, Microsoft on les aime, on leur fait des gros bisous. Grâce à eux l'informatique c'est simple, rapide et ouvert à tous.
... Ok donc je disais, on encode en ✌️EUC-KR✌️ puis on décode en ✌️Shift-JIS✌️ et là !
>>> c.encode("cp949").decode("shift-jis-2004")
'>'
tadaaaa, le > sort du chapeau !
Donc, si quelqu'un sur ordi Windows configuré pour le coréen enregistre un fichier texte avec le caractère "걚" dedans, la suite d'octets qui sera effectivement sur le disque pour représenter ce caractère sera la mème que celle utilisée pour le caractère ">" sur un ordi Windows configuré pour le japonais.
"Mais alors ok c'est bien, le mec à trouvé une manière de faire comprendre "flèche" à jubeat analyser via un encodage coréen, mais du coup pourquoi le fichier fonctionne alors que si on le lit en ✌️Shift-JIS✌️ ça ressemble à ça"
、ア、ア、ア、ア
、ア、ア、ア、ア
、ア、ア、ア、ア
、ア、ア、ア、ア
----
、ア、ア15、ア
、ア13、ア、ア
、ア0511、ア
01090307
----
01、ア、ア07
、ア0903、ア
0513、ア11
、ア、ア、ア15
----
"C'est pas plutôt censé ressembler à ça ?"
□□□□
□□□□
□□□□
□□□□
----
□□15□
□13□□
□0511□
01090307
----
01□□07
□0903□
0513□11
□□□15
----
Les 、ア ne gênent pas jubeat analyser pour une autre raison :
Il est ultra permissif sur les caractères autorisés dans les petites grilles
En fait dans la partie position, tout ce qui n'est pas :
- un des nombres cerclés ①, ②, ③, ④ (pas utilisés par ce fichier)
- un des symboles qui vient d'une définition (les trucs qui ressemblent à
*04:0.75en début de fichier) - au moins deux tiret en début de ligne (qui sert à marquer la fin de section)
jubeat analyser s'en fout complètement.
La doc explique qu'on peux se servir de ce principe à son avantage pour décorer un peu ses partition. Par exemple pour rendre plus clair qu'un bouton est actuellement occupé par une note longue, comme ici :
①――< |①---|
□□□□ |----|
□□□□ |----|
□□□□ |----|
■□□□ |----|
□□□□ |----|
□□□□ |----|
□□□□ |----|
①□□□ |①---|
□□□□ |----|
□□□□ |----|
□□□□ |----|
Le "■" n'est pas interprété d'une quelconque manière, il est juste ignoré.
C'est grâce à ça que jubeat analyser s'en sort malgré un fichier rempli de 、ア
Au passage ces 、ア sont là parce que l'auteur a utilisé "ㅁ" (U+03141 : HANGUL LETTER MIEUM) dans son fichier au lieu de "□" (U+025A1 : WHITE SQUARE). Une fois encodé puis décodé de la même manière que celle qu'on vient de voir ça donne bien 、ア
>>> "\u3141".encode("cp949").decode("shift-jis-2004")
'、ア'
Ok c'est bien beau tout ça
Mais comment je fais pour gérer ce bordel ? Je ne peux pas juste ignorer les mauvaises séquences d'octets, python plante si le fichier est pas entièrement correct
Mauvaise idée : Se replier sur un décodage ✌️EUC-KR✌️ si ça marche pas en ✌️Shift-JIS✌️
Mauvaise idée, je vois déjà arriver la troisième personne avec son fichier en encodage chinois, puis une autre avec le vietnamien etc etc etc. Faire ça c'est m'engager à maintenir une liste d'encodages valides, choisir dans quel ordre les essayer blablabla. Aussi ce qui va vraiment être chiant c'est qu'il va falloir que je mettre des cas particuliers partout dans le code en fonction des encodages pour dire "si c'est du coréen, utilise ces symboles pour les flèches, sinon si c'est du chinois etc etc etc" et aussi les cas particuliers de cas particuliers que je ne vais pas voir arriver
Moins mauvaise idée : Gérer tout au niveau octets sans essayer de décoder
Ça ça devrait marcher un peu mieux, mais c'est un effort vachement conséquent, il va falloir que je repasse par petites touches PARTOUT dans le code pour que ça soit géré correctement. Mais au moins on est sur que mon code fera exactement la même chose que jubeat analyser. (à savoir un peu de la merde quand même)
Au début je pensais vraiment que j'allais devoir faire ça, puis j'ai eu un flash
BONNE IDÉE : ignorer les mauvaises séquences d'octets
En fait je l'avais oublié, mais si, python peux très bien ignorer les erreur de décodage quand on lui demande de lire un fichier. Il a même plusieurs manières de le faire, toutes documentés
Dans mon cas précis j'ai choisi surrogateescape pour pouvoir conserver exactement les octets invalides, il le faut parce que il y a UN bout du code qui a réellement besoin d'utiliser un trick à base de longueur du texte en octets (donc encodé) pour pouvoir lire correctement une partie des fichiers, du coup il me faut les octets originaux, au cas où, même si ils ne représentent pas du ✌️Shift-JIS✌️ valide.
Gérer le problème comme ça a l'énorme avantage d'être très peu intrusif : le code continue à manipuler des str de bout en bout et j'ai juste à ajouter errors="surrogateescape" aux entrées/sorties.
Pour une fois, tout est bien qui finit bien
Je rajoute un cas de test avec les deux fichiers d'exemple, ça fonctionne, nouveau patch déployé dans la journée.
Vous pouvez désormais balancer des fichiers immondes à jubeatools 1.1.3, il devrait s'en sortir.
Merci à Nomlas et Mintice pour avoir trouvé ce bug !