Peu importe à quel niveau vous bossez sur la stack technique, il y a cette espèce de sous-entendu que les personnes qui travaillent "en dessous" de vous ont un job plus chiant (et inversement). Pour une certaine définition de "la stack technique", les gens qui gèrent les formats de fichiers sont tout en bas de l'échelle et doivent de ce fait se débattre avec les trucs les plus ignobles. Enfin du moins c'est maintenant ce que je crois après m'être forcé à écrire un parser+dumper pour un format de fichier (bientôt) legacy pour un jeu de rythme japonais.
Vous vous demandez sans doute comment cela m'est arrivé
J'adore les jeux de rythme, je suis un grand fan depuis ... ben heu depuis toujours en gros. Pendant un moment j'ai beaucoup, beaucoup joué à jubeat en particulier.
(sur cette vidéo c'est moi)
Dans ce jeu les boutons forment une grille de 4×4. Ils sont transparents et vont par dessus l'écran, de cette manière l'écran peut vous indiquer la prochaine touche sur laquelle vous devez appuyer avec une petite animation sous le bouton. Et comme toujours dans les jeux de rythme tout est synchronisé avec le rythme de la musique que vous avez choisi. Jubeat est très accueillant pour les débutants tout en offrant suffisamment de challenge aux niveaux supérieurs.
J'adore jubeat. En fait j'aime tellement ce jeu que je voulais pouvoir mettre mes propres chansons dessus. Malheureusement, contrairement à (par exemple) DDR avec Stepmania, la "scène" simulateurs pour jubeat est très peu développée pour une raison que j'ignore. Certains programmes existent, comme jubeat analyser ou jubeat analyser append, mais pour une raison que j'ignore il y a à peu près zéro contenu pour aller avec.
Au début je ne savais pas trop pourquoi ça avait l'air aussi mort, mais en tout cas ce qui m'a marqué quand j'ai essayé de créer mes propres chansons, c'est que ces deux simulateurs utilisent un format texte custom pour stocker les "partitions" et il n'existe pas de logiciel GUI utilisable qui le gère, comme ce que Stepmania peut proposer.
Ah tu veux créer des chansons hein ? Éditeur texte. Pas la meilleure ergonomie qui soit. J'ai trouvé ça tellement décourageant que j'ai décidé d'améliorer moi même la situation.
Donc, pour une raison que je ne pouvais plus tellement ignorer, j'allais désormais me lancer dans l'écriture de mon tout premier parser pour un format de fichier peu connu, et wow ... j'étais pas prêt.
Voici memo
Ou du moins ce que la plupart des gens voient quand ils ouvrent les fichiers de ce format pour la première fois, là au fait c'est juste du mojibake. La plupart des éditeurs texte ne reconnaissent pas automatiquement que ces fichiers sont encodés en ✌️Shift-JIS✌️ (remarquez les guillemets avec les doigts).
S'il y a une chose que j'ai apprise en parsant ce format, c'est la signification du mot endémique
Ce format :
- a été créé par des Japonais, pour le Japon
- a son implémentation "de référence" écrite en HotSoup (un dérivé japonais du BASIC)
- utilise un encodage de texte japonais (sujet qui en lui même est également un autre délire complet)
{kind=link}
Cependant, une fois décodé correctement, il est pas si moche, au contraire même. Il utilise un agencement visuel pour marquer la position des notes ainsi que leur chronologie :
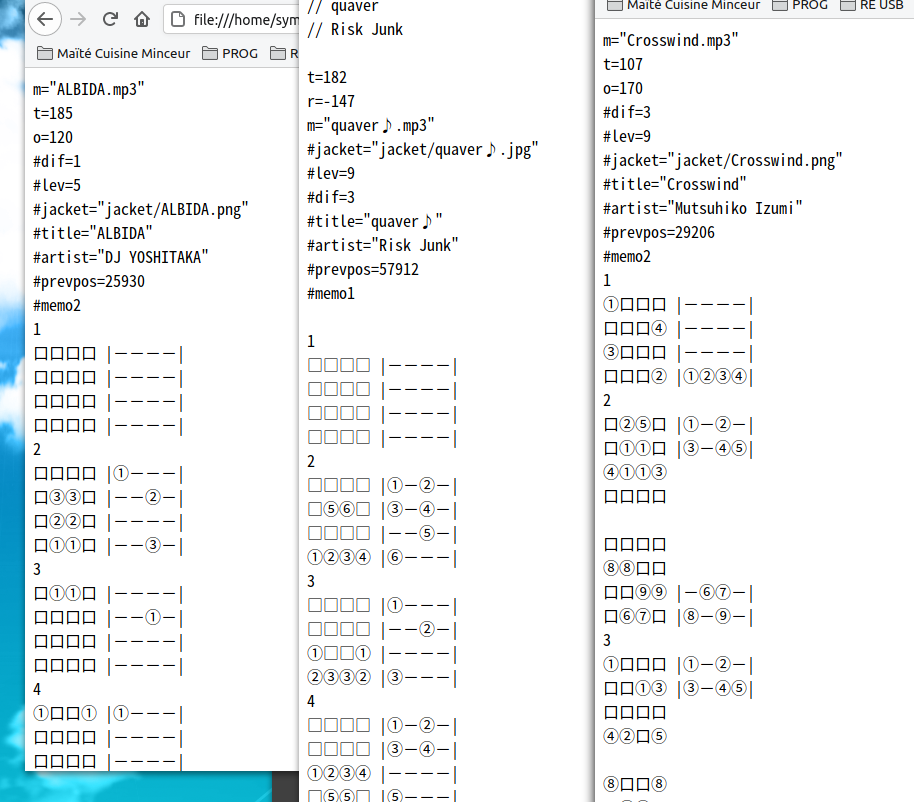
Comme vous pouvez le voir il y a un petit peu de métadonnées au début, et ensuite commence une séquence de blocs numérotés. Pour chaque bloc, la partie gauche indique la position des notes, et la droite leur timing.
Au fil de ma lecture de l'unique forme de documentation existante sur le format (qui étonnement existe tout court), j'ai découvert qu'il avait en fait été conçu pour permettre à n'importe qui de copier le texte de sites comme cosmos memo dans un fichier, balancer quelques tags au début, et avec un bidouillage minimal, obtenir un fichier texte que jubeat analyser peut comprendre. Fût un temps, les sites "memo" étaient l'unique source d'information fiable si vous vouliez avoir les "partitions" pour chaque chanson du jeu sans devoir aller dans une salle d'arcade. Les joueurs les plus hardcore utilisaient certainement l'info contenue sur ces sites comme matériel d’entraînement. Le créateur (la créatrice ?) de jubeat analyser a probablement vu ça et décidé de ne pas aller à contre courant en créant un "vrai" format à partir de la représentation textuelle et visuelle que ces sites avaient choisi.
Comme c'est souvent le cas avec les trucs informatiques "visuels" (je pense par exemple à la programmation par nœuds ou blocs en cliquer/glisser), une idée qui a priori semble "bonne" va souvent plus tard se révéler être quelque part à mi-chemin entre "très contraignante" et "complètement barge" quand il faudra que quelqu'un fasse effectivement marcher la chose.
Faire effectivement marcher la chose
"OK, voyons, je vais juste lancer Python et ..."
Python 3.9.0 (default, Oct 25 2020, 19:44:11)
[GCC 7.5.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> open("sigsig 3.txt").readlines()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/symeon/.pyenv/versions/3.9.0/lib/python3.9/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8c in position 137: invalid start byte
>>>
"... oh ... ok, ouais, d'accord ... ✌️Shift-JIS✌️, on va retenter."
Heureusement Sam & Max m'avaient adéquatement averti que les encodages, ça existe, et c'est compliqué, et que dieu merci Python est l'un des rares langages à ne pas être dans le déni à ce niveau là et à proposer un support non-merdique pour ça en standard (du moins à partir de Python 3.0, pour les moins jeunes qui ont encore des mauvais souvenirs de Python 2.x)
"Du coup si je réessaye en précisant l'encodage ..."
>>> open("sigsig 3.txt", encoding="shift-jis").readlines()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'shift_jis' codec can't decode byte 0x87 in position 224: illegal multibyte sequence
>>>
"MAIS MERDE ? JE PENSAIS QUE PYTHON GÉRAIT CORRECTEMENT L'ENCODAGE ?"
Eh bien, ce que j'ai déduit, c'est qu'en fait, quand les Japonais vous parlent de ✌️Shift-JIS✌️ dans leur documentation, ce qu'ils entendent réellement par là inclus à coup quasi-sûr une extension non-standard de cet encodage. Extension qui sans surprise correspondra comme par hasard aux débilitudes patrimoniales que Windows gère par défaut quand il est configuré pour le marché japonais.
Je le répète : encodage japonais = autre délire complet à lui tout seul = ne PAS se pencher
Après avoir observé directement les octets utilisés pour encoder les nombres cerclés et beaucoup, BEAUCOUP de recherche. J'ai trouvé un site qui montrait un tableau de caractères qui avait l'air de correspondre. Il s'avère que Python appelle cet encodage shift-jis-2004 au lieu de juste shift-jis. J'ai encore du mal à me remettre du fait que Firefox arrive à correctement afficher ces fichiers juste en lui indiquant qu'ils utilisent un encodage "Japonais", sans plus de précisions.
"Ok bon maintenant j'ai le texte "brut", on continue ... quelques tags facilement regexables, puis des blocs de 4x4 sur la gauche avec 4 barres de 4 battements sur la droite ... les blocs sont séparés par du blanc ou des numéros. Ça peut pas être si dur que ça ..."
"... attends, wtf, c'est quoi ces symboles 口 ? C'est pas censé être □ U+25A1 WHITE SQUARE ?"
C'est le kanji pour "bouche", par coïncidence ça ressemble beaucoup à un carré blanc, surtout sur les écrans basse-résolution. Le format memo permet d'utiliser les deux de manière presque interchangeable.
"Ok bon, pas grave, je peux coder ça, c'est bon, c'est facile ..."
"... Aaaaaattends un peu, c'est quoi ça ?"
57
⑩口口⑨ |①--②③④|
②③④⑤ |⑤-⑥-|
⑧⑩口① |⑦-⑧-|
口口⑦⑥ |⑨-⑩-|
Vous voyez la première barre à droite ? Elle fait 6 caractères de long au lieu de 4. Ça ne veut pas dire qu'elle dure plus longtemps mais plutôt qu'ici la durée d'une barre "normale" est divisée en 6 battements au lieu de 4. Jusqu'ici on ne l'avait pas rencontré parce que dans 95% des cas le timing des notes tient dans une barre divisée en 4. Mais ça n'est pas toujours le cas, comme Adam Neely m'en avait déjà parlé. De ce fait le format memo permet une subdivision flexible des barres. Les barres peuvent changer de subdivision à n'importe quel endroit dans le fichier, ce qui signifie par exemple que le dernier extrait est équivalent à ça
57
⑩口口⑨ |①-----②-③-④-|
②③④⑤ |⑤⑥|
⑧⑩口① |⑦--⑧--|
口口⑦⑥ |⑨---⑩---|
C'est juste que c'est plus facile à lire quand c'est écrit de l'autre manière.
"Bon ... d'accord ... je vais devoir sortir les nombres chelou pour ça, mais c'est encore jouable ..."
"... mais attends, c'est quoi ça maintenant ?"
4
□③①□ |①-②-|
□②④□ |③④⑤-|
□□□□
□⑤□□
□□□□
⑥□⑨⑥
□□□□ |⑥-⑦-|
□□⑦⑧ |⑧-⑨-|
Attention les yeux, dans ce bloc (remarquez que la deuxième partie n'est pas numérotée "5", donc ces deux trucs forment un seul "bloc"), les notes ④ et ⑨ sont dans la même position, mais arrivent à des moments suffisamment éloignés dans le temps pour ne pas se chevaucher visuellement quand les notes défilent. Pour faciliter la lecture, ce bloc est découpé en deux sous-bloc de 2 barres.
Revoilà le même bloc, mais j'ai seulement laissé ④ et ⑨ :
4
□□□□ |----|
□□④□ |-④--|
□□□□
□□□□
□□□□
□□⑨□
□□□□ |----|
□□□□ |--⑨-|
Remarquez que les deux notes sont sur le même bouton, mais à quelques battements l'une de l'autre.
Les subdivisions de bloc comme celle là peuvent arriver à n'importe quel moment dans le fichier, sans prévenir, et le code de mon tout premier essai n'aimait vraiiiiment pas ça. Je suis resté bloqué à ce point là pendant un lonnnnng moment quand je venais d'apprendre Python et qu'écrire ce parser était en gros mon tout premier projet personnel de programmation.
On est maintenant des années plus tard au moment ou j'écris cet article, j'ai enfin réussi à gérer ce cas. C'est tout ce que t'as dans le ventre memo ?
Bien sûr que non.
①⑩⑩④ |(135)①②③④|
□⑤②□ |⑤⑥⑦⑧|
⑦⑨⑨⑦ |-⑨-⑩|
⑧③⑥⑧ |(540)-|
①⑩⑬④ |(135)①②③④|
⑭⑤②⑭ |⑤⑥⑦⑧|
⑦⑫⑨⑦ |⑨⑩⑪⑫|
⑧③⑥⑪ |(270)⑬⑭|
①⑩⑩④ |(135)①②③④|
□⑤②□ |⑤⑥⑦⑧|
⑦⑨⑨⑦ |-⑨-⑩|
⑧③⑥⑧ |(540)-|
Vous voyez les nombres entre parenthèses dans la partie timing ? Ce sont des changements de BPM, ils peuvent arriver à n'importe quel endroit et n'ont plus ou moins rien à voir avec les notes, ils indiquent juste que le tempo de la chanson change à cet endroit. SI vous avez été assez malin pour ne pas stocker le timing des notes en secondes mais à la place en temps symbolique (en fraction de battements), ça ne devrait pas vous poser problème. (C'est un très très gros "si" soyons clair)
Si vous avez trouvé que tout ce qui précède était compliqué, ne vous inquiétez pas :
- vous n’êtes pas seul
- y'en a encore
Jubeat a ajouté des notes longues à l'occasion d'une nouvelle version, ce qui veux dire que certaines notes demandent maintenant d'appuyer mais aussi de maintenir pendant un temps donné. C'est un élément de gameplay intéressant, les chansons les plus dures les utilisent pour forcer à taper certains motifs à une seule main pendant que l'autre est occupée à maintenir une note longue. Jetez rapidement un coup d’œil à la façon dont elles sont affichés dans le jeu :
Elles sont donc en forme de flèche avec une pointe en triangle qui se rétracte vers le bouton maintenu. Quand la flèche est complètement rentrée, la note est terminée. c'est choupi.
Maintenant est-ce que vous sauriez deviner comment les notes longues ont été bodgées dans le format ?
C'est ça, visuellement encore.

Ouch.
Maintenant votre code doit réussir à parser correctement des chefs-d’œuvre tels que ce quadruple bloc
13
口口口② |①-②-|
口口口|
①口口∧
口口口②
③―<③
口口口口 |--③-|
口口口口
口口口口
④口口口
∨口口口
|口口口 |--④-|
④口口口
口口口口
口⑤⑤口
口口口口
⑤口口口 |--⑤-|
Les tiges des flèches sont absolument optionnelles au passage, ça marche juste en mettant les symboles triangulaires.
Et d'abord c'est quoi ces symboles triangulaires ?
La doc indique d'utiliser
'>' # U+0FF1E : FULLWIDTH GREATER-THAN SIGN
'∨' # U+0FF36 : FULLWIDTH LATIN CAPITAL LETTER V
'<' # U+0FF1C : FULLWIDTH LESS-THAN SIGN
'∧' # U+02227 : LOGICAL AND
Mais en vrai un fichier memo sauvage observé dans son habitat naturel peut très bien utiliser n'importe lesquels de ceux là :
LONG_ARROW_RIGHT = {
">", # U+003E : GREATER-THAN SIGN
">", # U+FF1E : FULLWIDTH GREATER-THAN SIGN
}
LONG_ARROW_LEFT = {
"<", # U+003C : LESS-THAN SIGN
"<", # U+FF1C : FULLWIDTH LESS-THAN SIGN
}
LONG_ARROW_DOWN = {
"V", # U+0056 : LATIN CAPITAL LETTER V
"v", # U+0076 : LATIN SMALL LETTER V
"Ⅴ", # U+2164 : ROMAN NUMERAL FIVE
"ⅴ", # U+2174 : SMALL ROMAN NUMERAL FIVE
"∨", # U+2228 : LOGICAL OR
"∨", # U+FF36 : FULLWIDTH LATIN CAPITAL LETTER V
"∨", # U+FF56 : FULLWIDTH LATIN SMALL LETTER V
}
LONG_ARROW_UP = {
"^", # U+005E : CIRCUMFLEX ACCENT
"∧", # U+2227 : LOGICAL AND
}
La fin d'une note longue est juste indiquée par une autre note normale plus tard sur le même bouton que celle avec la tige, comme ça :
①――< |①---|
□□□□ |----|
□□□□
□□□□
②□□□
□□□□
□□□□ |----|
□□□□ |--②-|
De cette manière la note longue commence en ① et dure jusqu'a ②
On peut aussi remarquer que, quand la note longue est verticale, le caractère utilisé pour dessiner la "tige" est exactement le même que celui utilisé comme délimiteur de la partie temporelle (U+FF5C FULLWIDTH VERTICAL LINE), j'espère que votre code gère ça d'une manière où d'une autre.
Oh et au fait, maintenant on a droit à des AMBIGUITÉS :
①①<< |①---|
□□□□ |----|
□□□□ |----|
□□□□ |----|
Regardez moi bien ça.
Est-ce que c'est :
- deux
①―<? - un
①――<et un①<?
On sait pas !
Le seul truc qu'on sait c'est que vous allez devoir réécrire votre parser de A à Z !
Arrivé à ce moment précis je suppose que certains d'entre vous sont déjà en train de chercher une excuse pour rejeter ce cas sur la base du fait qu'il est déraisonnable. Et c'est pas grave, on s'inflige tout cet exercice nous même de toute façon. Je pense que la plupart des gens iront dormir sur leurs deux oreilles en sachant parfaitement que leur code ne gère "que" 99% des cas.
Mais pour les autres qui ne veulent pas se laisser abattre, je continue à creuser ...
Vous pensez que vous avez trouvé une manière rapide de traiter le premier cas ? Essayez avec ça !
□□□□ |①---|
□①□□ |----|
>①①< |----|
□∧□□ |----|
Le ① en bas à gauche à 3 flèches qui pointent vers lui !
Oh, et toi petit malin, tu crois que je t'ai pas vu toi à essayer de faire passer en douce un solveur de CSP ?
Et celui là alors ?
□∨□□ |①---|
□①□□ |----|
□□□□ |----|
>①□① |----|
Peu importe le code que vous allez pondre, vous devriez trouver trois solutions :
□∨□□ □□□□ □□□□
□●□□ + □□□□ + □□□□
□□□□ □□□□ □□□□
□□□□ >●□□ □□□●
ou
□∨□□ □□□□ □□□□
□●□□ + □□□□ + □□□□
□□□□ □□□□ □□□□
□□□□ >――● □●□□
ou
□∨□□ □□□□ □□□□
□|□□ + □□□□ + □●□□
□|□□ □□□□ □□□□
□●□□ >――● □□□□
À ce moment là vous avez un choix, vous pouvez soit résister à la tentation de deviner, et déranger votre humain avec une question, soit trouver une manière pédante d'expliquer que vous êtes juste en train de deviner (avec en général le mot "heuristique"). Dans ce cas d'exemple en plus ça a l'air raisonnable de deviner : on sais pertinemment qu'il ne faut garder que la première solution, ça parait improbable qu'un humain normalement constitué ai écrit les deux autres solutions comme ça.
Donc maintenant non seulement il vous faut un genre d'algo avec backtracking pour les cas les plus compliqués, mais en plus il faut que vous trouviez une ✨heuristique✨ pour deviner ce que voulais dire l'humain qui a écrit ce fichier.
Pour l'algorithme, c'est maintenant ou jamais si vous voulez vous la péter avec l'énorme quantité de savoir que vous avez gardé de vos cours d'informatique. Personnellement j'ai décidé que je n'avais rien à prouver ici et/ou pas de temps à perdre et j'ai utilisé un solveur CSP tout fait, nommément python-constraint (API sublime au fait, j'adore quand c'est aussi bien foutu !)
Modéliser le problème comme un CSP est étonnement clean.
- Les symboles triangulaires des flèches vont être nos variables
- Le domaine (valeurs possibles) d'une flèche donnée sera tous les nombres cerclés dans sa direction
- La seule contrainte sera que toutes les flèches doivent "choisir" un nombre cerclé différent
En python ça devient
import constraint
problem = constraint.Problem()
for arrow_pos, note_candidates in arrow_to_note_candidates.items():
problem.addVariable(arrow_pos, list(note_candidates))
problem.addConstraint(constraint.AllDifferentConstraint())
solutions = problem.getSolutions()
J'adore la ligne solutions = problem.getSolutions().
L'heuristique n'était pas simple à trouver non plus, ma première idée c'était de minimiser la longueur totale des tiges, mais ça voudrait dire que dans ce cas :
①①<< |①---|
□□□□ |----|
□□□□ |----|
□□□□ |----|
Les deux solutions
●――< □●<□ ●―<□ □●―<
□□□□ + □□□□ et □□□□ + □□□□
□□□□ □□□□ □□□□ □□□□
□□□□ □□□□ □□□□ □□□□
seraient à égalité et je voulais vraiment que la deuxième gagne (car la doc dit spécifiquement que le parser de référence interprète ce cas de cette manière).
Ce que j'ai fini par utiliser c'est un tri lexicographique sur les tuples (#3s, #2s, #1s) (nombre de tiges de longueur 3, 2, 1), c'est facile à coder mais j'aurai du mal à expliquer intuitivement comment ça se comporte ...
Quand même, vous vous rendez compte qu'on est sérieusement en train de parler de solveur CSP et d'heuristique juste pour parser un fichier texte ?
MAIS LE FUN NE S'ARRÊTE PAS LÀ
Et si jamais l'auteur du fichier avais envie de distinguer plus clairement une note normale d'une note utilisée pour marquer la fin d'une note longue ? Eh bien c'est possible, la doc spécifie que si on met une ligne #circlefree=1 dans les métadonnées en haut on peut maintenant écrire ça
∨∨∨∨ |①---|
□□□□ |②---|
①②③④ |③---|
□□□□ |④---|
□□□□
□□□□
234□
□□□□
Et oui, ces 234 sont bien des caractères pleine chasse. Les trois premières notes longues se terminent maintenant aux instants décrits par ②, ③ et ④ dans la partie timing.
Maintenant respirez un coup
Faites une pause
Méditez.
Y'a quoi après 9 ?
∨□□□ |⑨---|
□□□□ |----|
⑨□□□
□□□□
□□□□
□□□□
10□□□ |----|
□□□□ |--⑩-|
Une autre hypothèse fondamentale a été réfutée, veuillez conserver votre calme
oui ... c'est "legal" d'après la doc ...
Et oui, c'est "10" en deux caractères.
Si mes bidouillages de polices ont fonctionné, vous devriez voir que ce "10" a l'air aussi large qu'un seul carré blanc. Ça imite la manière donc ce texte serait affiché sur les anciens ordinateurs japonais (et bien sûr Windows) dans la plupart des cas. Évidemment c'est juste la représentation à l'écran, dans les faits la partie position de cette ligne fait maintenant 5 caractères de long. Ce qui veut dire que ton parser doit d'un coup gérer le fait que la partie position d'une ligne peut faire aléatoirement entre 4 et 8 caractères ...
Comment on gère ça ? Si vous êtes un vrai nerd Unicode vous êtes peut-être au courant de l’existence des Propriétés de Caractères, en particulier la Largeur Est-Asiatique. Ça peut marcher, mais que faire si un unique caractère étroit se glisse dans le texte à un endroit ? Et comment on gère les 10000 façon de noter la pointe d'une flèche ? Y'a forcément certaines d'entre elles qui sont généralement affichés en pleine chasse mais qui ne sont pas considérées comme pleine chasse par le standard ?
Ici, je pense qu'essayer de résoudre ce problème au niveau Unicode c'est se créer un autre problème. Si vous acceptez le fait que la vraie nature des fichiers memo, c'est une suite d'octets qui représentent du texte encodé en ✌️Shift-JIS✌️ et que tout ce bordel Unicode n'est qu'une représentation intermédiaire qu'on utilise pour gérer le texte en transit, la doc vous donne une solution immonde, mais simple :
On fout un tag #bpp=1 or 2 (bytes per panel) au début, et on découpe les octets du texte de la partie position encodée en ✌️Shift-JIS✌️ tous les 1 ou 2 octets en fonction du tag.
Yep, ça "marche" parce que par miracle les caractères pleine chasse qui nous intéressent ici s'encodent tous avec 2 octets, alors que les demi-chasses un seul.
Et c'est avec ce dernier bodge que je clos cet article pour aujourd'hui.
Merci de m'avoir lu !
Si ça vous a paru horrible, souvenez vous que c'était juste une visite guidée de certains problèmes, et que je n'ai parlé que d'une partie des solutions.
La morale de l'histoire c'est que je ne veux plus jamais devoir toucher à ce format, et aussi que je suis en train de travailler pour créer un écosystème complet autour d'un nouveau format qui est juste un fichier JSON avec un schéma définit (OUI. JE SAIS.). Vous voulez utiliser vos fichiers memo avec mes outils ? Je fournis un convertisseur, mais c'est tout. Comme ça ce convertisseur est le seul bout de code qui a besoin de gérer des fichiers memo, et techniquement je n’empêche pas les gens de continuer à l'utiliser si ils veulent.
Si vous voulez voir (beaucoup plus) de code, le convertisseur s'appelle jubeatools et est ici. Je pense qu'il est pas loin d'avoir la ré-implémentation la plus complète du format, mais il y a encore des choses dont la doc parle que je n'ai pas eu la force d'ajouter, comme les notes longues sans flèche (n'existe pas dans le jeu jubeat original, l'implémentation casse encore plus d'hypothèses sur la partie position des blocs), ou cette notation chelou qui est utilisée par jubeat analyser pour afficher des groupes de notes avec des couleurs spécifiques (ce qui n'a aucun impact sur la position ou le timing des notes).
Comme jubeatools (le convertisseur) est conçu pour être bidirectionnel, j'ai aussi écrit un dumper pour les fichiers memo. Avoir une paire encodeur / décodeur comme ça ça permet facilement d'utiliser des framework de test proprety-based comme hypothesis. Hypothesis demande un certain effort, ça a pas été super facile de s'habituer à ces concepts et d'écrire le code qui génère des fichiers memo. Mais une fois que c'est fait vous êtes pleinement libre d'apprécier à quel point hypothesis DÉFONCE. Ça trouve des bugs instantanément. À un moment je pensait que ça devenait lent, tellement lent que je devait couper après plusieurs minutes passées à visiblement rien faire. En réalité ça avait découvert une entrée qui provoquait une boucle infinie dans mon code 😅. Le désavantage principal d'hypothesis c'est que c'est réduit à quelques motifs de test spécifiques ou ont peut vraiment l'utiliser correctement, comme le susnommé encodeur / décodeur. Mais si il se trouve que ce que vous faites correspond à un de ces motifs, essayez le. J'ai jamais été aussi confiant en mon code, c'est vraiment d'un autre niveau.
Bonus round !
jubeat analyser est en fait compatible avec 4 formats différents. Je n'ai présenté que le plus récent, #memo2, il y a aussi #memo1, #memo, et le format à une seule colonne qui n'a pas de nom. Il différent tous de manières subtiles qui les rendent (surtout #memo et #memo1) uuultra chelou à lire+écrire. Peut-être pour un autre article !