In my last post I've been telling you about jubeatools, a tool to convert between several jubeat chart formats that I code as a hobby. I recently started working on it again, having felt a sudden motivation boost from receiving a cry for help from someone who had found a bug while trying to use it.
This blog post won't talk about this person's bug (which wasn't that special), but rather about another bug on which I've just stumbled (thanks to hypothesis) once again).
#memo
As mentioned at the end of my previous post, jubeatools does not only deal with the format I've previously described. What I've been writing about is #memo2, the more modern but also the less fugly one of the 4 formats that make up the jubeat analyser format "family". There's also #memo, #memo1, and a format with no dedicated tag that's referred to by the docs as something like "the mono-column format" ("1列形式" in the text).
Our bug of interest today had to do with the chunk of code that deals with the #memo format, a dodgy mix between mono-column and #memo2.
#memo looks a lot like #memo2 on the surface, but with one big quirk : the timing part behaves differently. In #memo, each symbol on the timeline represents a fixed 1/4 beat duration. If your chart doesn't have anything but quarter notes, the format keeps it visually identical to #memo2 :
□①①□ |①-②③|
□□□□ |④⑤⑥⑦|
③⑦□④
②⑤⑥②
⑭⑪⑫⑭
□⑨⑩□
□□⑧□ |⑧⑨⑩⑪|
⑬□□⑬ |⑫⑬-⑭|
⑭⑪⑫⑭ |-①②③|
⑦⑨⑩⑧ |④⑤⑥⑦|
⑤③④⑥ |⑧⑨⑩⑪|
⑬①②⑬ |⑫⑬-⑭|
As you can see, we get to keep the familiar two-column layout from #memo2, with position on the left and timing on the right, and also the famous circled numerals are here.
Up until now, nothing new.
However, if you need to write notes that fall on thirds of the main pulse, also known as triplets for the ones in the back that need to flaunt how they went to music school, then things start to get complicated.
While in #memo2 you can just put bars of length 3 like this :
34
④⑤⑥口 |①-②|
口⑦⑧⑨ |③--|
③口口③ |④⑤⑥|
②①①② |⑦⑧⑨|
35
④⑤⑥口 |①-②|
口⑧口⑦ |③--|
③口口③ |④⑤⑥|
②①①② |⑦-⑧|
In #memo you can't, so instead you have to do this:
*①:0.000
*③:0.667
*④:1.000
*⑦:2.000
*⑧:2.333
*⑨:2.667
*⑩:3.000
*⑪:3.333
*⑫:3.667
⑦⑧⑨□ |----|
□⑫⑪⑩ |----|
④□□④ |----|
③①①③ |----|
⑦⑧⑨□ |----|
□⑫□⑩ |----|
④□□③ |----|
③①①④ |----|
The line at the top that look like *⑫:3.667 are symbol definitions, here for instance it means that ⑫ corresponds to a note that happens at time 3.667 (≈ 3 + 2/3 beats)
(symbolic time, as in measured in beats and not in seconds)
(time relative to the start of the bloc, so here two thirds of the way on the fourth bar of the bloc, no matter the bloc)
This means you don't need to put a symbol on the timeline to be able to use it on the position part. Instead as shown above you can define the time the symbol corresponds to in advance, often right before the block that uses it.
But, notice that you still need to put in some empty |----|s on the right. This is because if you don't leave them in, the position parts without any |----|s associated will be understood as the continuation of the previous block's definition, but spread out to ease reading. Time does not move forward if there are no |----|s.
Anyways, as you may have guessed, a real pleasure to parse and make sense of.
Good test, good bug
Thankfully this format (as all the other ones for now) has an associated unit test, and not just any kind of unit test, a test written with hypothesis !
In jubeatools I have an unbelievable luck : 99% of the useful code follows the encoder+decoder pattern, which makes for very good hypothesis tests. This pattern is here because for each format jubeatools handles, we have :
- A first representation (here,
#memo, the text format) - A second representation (my python object that holds the notes in the chart)
- An encoder+decoder function couple to switch between the two
Once you spot this pattern in your code, hypothesis is going to help you SO GODDAMN MUCH. You have no idea. This test pattern works so well, it's the one used to showcase how fire hypothesis is in the "Quick Start" part of the docs. iibh it's also kind of a way to make you forget for a moment how big of a topic finding other test patterns where the lib can actually be useful still is.
Bottom line is, if I want to test my code with hypothesis, I need to write a #memo decoder that gives python objects. But also a python object encoder that makes #memo files.
And it's all thanks to these two things that I was able to find my bug from outer space.
A clue to start off
Bonus challenge : guess the bug before the next part
The code that has to write a #memo file from the "pure" information (which note is where and when) needs to deal with the case where a note does not land on 1/4 beats, and accordingly has to create symbol definitions.
To make the code easier to write I had decided that none of my symbol definitions would overwrite a previous definition. A redefinition like this can totally happen in a wild #memo file encountered in its natural habitat. A bit like how the example above shows you can redefine the time associated with circles numbers. I did not want to have to deal with that in the dumping code since it seemed you didn't have to redefine symbols to write a correct file.
So, in my code, each new symbol definition uses a new character, chosen in order from a big string defined by this piece of code
# I put a FUCKTON of extra characters just in case some insane chart uses
# loads of unusual beat divisions
DEFAULT_EXTRA_SYMBOLS = (
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん"
"アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲン"
)
See the comment, full of hope.
That's the fullwidth uppercase alphabet, then lowercase, then hiragana, and finally katakana. Which comes to a grand total of 144 extra symbols, that looked like enough to me.
I agree that in general in code, choosing a fixed supply of anything whose consumption is unknown ahead of time and hoping that's enough reeks of amateurism. But the best thing is the bug I'm telling you about isn't even because of this. Well ... it's close ... but the bug is not that we run out of extra symbols.
Anyway, now that you know this, you're ready to understand the bug, surely some of you have already spotted it.
Uggh it froze
Today, my unit tests seem to get stuck on the test for the #memo format. I wonder how that could be, usually this particular one doesn't need more than a second to complete. I didn't really touch any logic in the load / dump part, but I'm just back from a big refactoring effort so I say why not.
The only time hypothesis really froze like that, it was because it had found an infinite loop in my code. To check if that's the case here, I just stop it while it's running to see if it's getting stuck at a specific point in the code ... nope, no luck, it's in a different spot every time.
I try and let it run for a while, after a good while, the test fails, and hypothesis comes back saying "hey I've got this failing example, I gave up trying to simplify it so here it is !" :
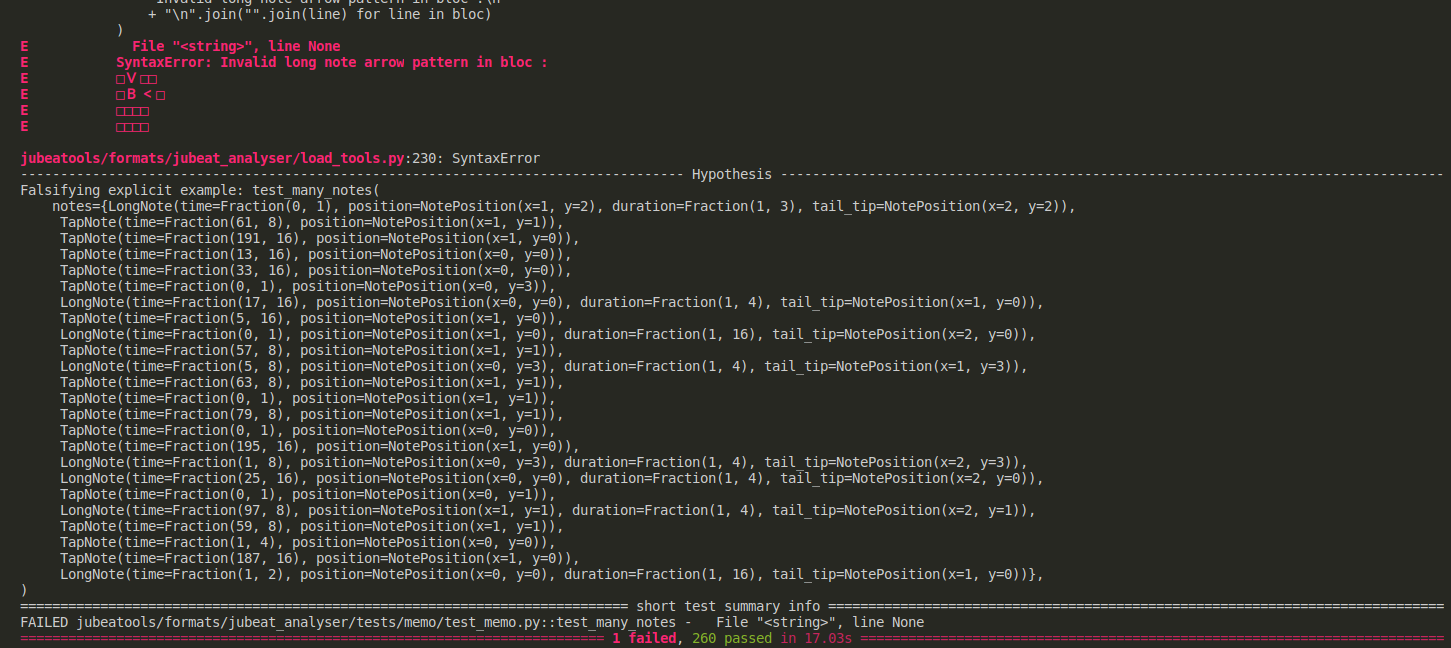
Wow indeed it's not very simple, 24 objects as a minimal reproducible example feels like the kind of bug you don't notice right away
Apparently my code isn't happy to have to deal with a block like this :
□∨□□
□B<□
□□□□
□□□□
with two arrows pointing towards the B at once. Well it's right, this is not a correct arrow pattern ... like we've seen in the previous post ...
I try to shorten the example myself, by telling myself the bug must be some kind of conflict in the long note printing code, but nothing to see there, if I only keep the long notes the bug disappears ...
On a similar idea, I wonder if the fact there are many notes all with weird timings in the same position as the B might be breaking the part of the code that deals with avoiding visual overlap in the position part ... but no, no luck either ... no error when I only keep in the notes in position (1,1).
So, got an idea ?
Spoiler
I now remember the way the test is written :
It's generating a bunch of python objects that represent notes, gives them to the encoder, then gives its text output to the decoder, and then checks that the notes recovered back are the same as the original ones. In a way, we're making sure that #memo as an intermediate representation properly keeps the note information, that the notes "survive" a round-trip to and from the text format.
So in the bug-causing case, what does this intermediate text look like ?
// Converted using jubeatools 0.1.1
// https://github.com/Stepland/jubeatools
t=120
m="."
o=0
#lev=0
#dif=3
#jacket="."
#holdbyarrow=1
#memo
*A:0.062500
*B:0.125000
*C:0.312500
*D:0.333333
*E:0.375000
*F:0.562500
*G:0.625000
*H:0.812500
*I:0.875000
*J:1.062500
*K:1.312500
*L:1.562500
*M:1.812500
*N:2.062500
①①<□ |①②③−|
①①□□
□①<□
①□□□
②A□□
□□□□
□□□□
B―<□
□C□□
□□□□
□D□□
E□□□
③<□□
□□□□
□□□□
□□□□
F□□□
□□□□
□□□□
G<□□
H□□□
□□□□
□□□□
I□□□
J<□□
□□□□ |−−−−|
□□□□
□□□□
K□□□
□□□□
□□□□
□□□□
L―<□
□□□□
□□□□
□□□□
M□□□
□□□□
□□□□
□□□□
N□□□
□□□□
□□□□ |−−−−|
□□□□ |−−−−|
*O:3.125000
*P:3.375000
*Q:3.625000
*R:3.875000
□□□□ |−−−−|
□□□□ |−−−−|
□□□□ |−−−−|
□□□□
□□□□
□O□□
□□□□
□□□□ |−−−−|
□□□□
□P□□
□□□□
□□□□
□□□□
□Q□□
□□□□
□□□□
□□□□
□R□□
□□□□
□□□□
*S:1.875000
*T:3.687500
*U:3.937500
□□□□ |−−−−|
□S□□ |−−−−|
□□□□ |−−−−|
□□□□
□T□□
□□□□
□□□□
□□□□ |−−−−|
□U□□
□□□□
□□□□
□□□□
*V:0.187500
□V□□ |−−−−|
□B<□
□□□□
□□□□
□□□□
□E□□
□□□□
□□□□
□□□□
□□□□ |−−−−|
□□□□ |−−−−|
□□□□ |−−−−|
Well wow that is long, really not a small example, but just lemme look for a sec ...
Oh cool ! Here's our block with the B ans the two arrows :
*V:0.187500
□V□□ |−−−−|
□B<□
□□□□
□□□□
□□□□
□E□□
□□□□
□□□□
□□□□
□□□□ |−−−−|
□□□□ |−−−−|
□□□□ |−−−−|
weird ... it defines symbol V and then uses it nowhere ...
wait ...
*V:0.187500
□V□□ |−−−−|
□B<□
□□□□
□□□□
WAIT ...
*V:0.187500
□V□□ |−−−−|
□B<□
□□□□
□□□□
IT ACTUALLY IS USED
show me the list of extra symbols real quick ?
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん
アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲン
and what does the list of allowed down arrow symbols look like again ?
- "V" # U+0056 : LATIN CAPITAL LETTER V
- "v" # U+0076 : LATIN SMALL LETTER V
- "Ⅴ" # U+2164 : ROMAN NUMERAL FIVE
- "ⅴ" # U+2174 : SMALL ROMAN NUMERAL FIVE
- "∨" # U+2228 : LOGICAL OR
- "V" # U+FF36 : FULLWIDTH LATIN CAPITAL LETTER V
- "v" # U+FF56 : FULLWIDTH LATIN SMALL LETTER V
woooooooow, OK
Basically
There was a clash between the extra symbols chosen by the dumper and the characters accepted as long note arrows tips by the parser. The dumper defines so many extra symbols that it reaches the V in the list. This same V is mistaken for a long note tip by the parser.
I'll let you appreciate how this precise error found by the test can only show up if :
- The group of notes you want to write uses so many symbol definitions that you reach the
V - AND the
Vgets put right above another note (in the position part) - AND this note under the
Vis also be a long note - AND the tip of the arrow of this long note does not clash with the
V's position
Really the test could have spotted variations of the observed error by verifying only the first condition.
But still ... wow ... long live property-based testing, use it, and dial in some big numbers when you want to have "fun"