
When sam & max said that encoding is complicated, I didn't think I'll ever need to go to the lengths this new bug in jubeatools took me.
For the newcomers to my blog, jubeatools is a command-line tool and hobby project of mine. It converts between several chart formats for a music game called jubeat. There are tons of video of people playing it on youtube if you want to see what the game looks like.
The main pain point in jubeatools is that it has to deal with one specific format familly : the "jubeat analyser" formats. I call them this way since they are the formats supported by the software with the same name. see my first post if you want to know more.
The one thing that matters for this article is knowing that, USUALLY, files in these formats are also text files properly encoded in ✌️Shift-JIS✌️.
Emphasis on "USUALLY" and the air quotes around ✌️Shift-JIS✌️
On a beautiful summer day ...
Someone sends me a message telling me jubeatools can't convert a file they found, jubeat analyser has no problem reading it though ...
I take a look at it :
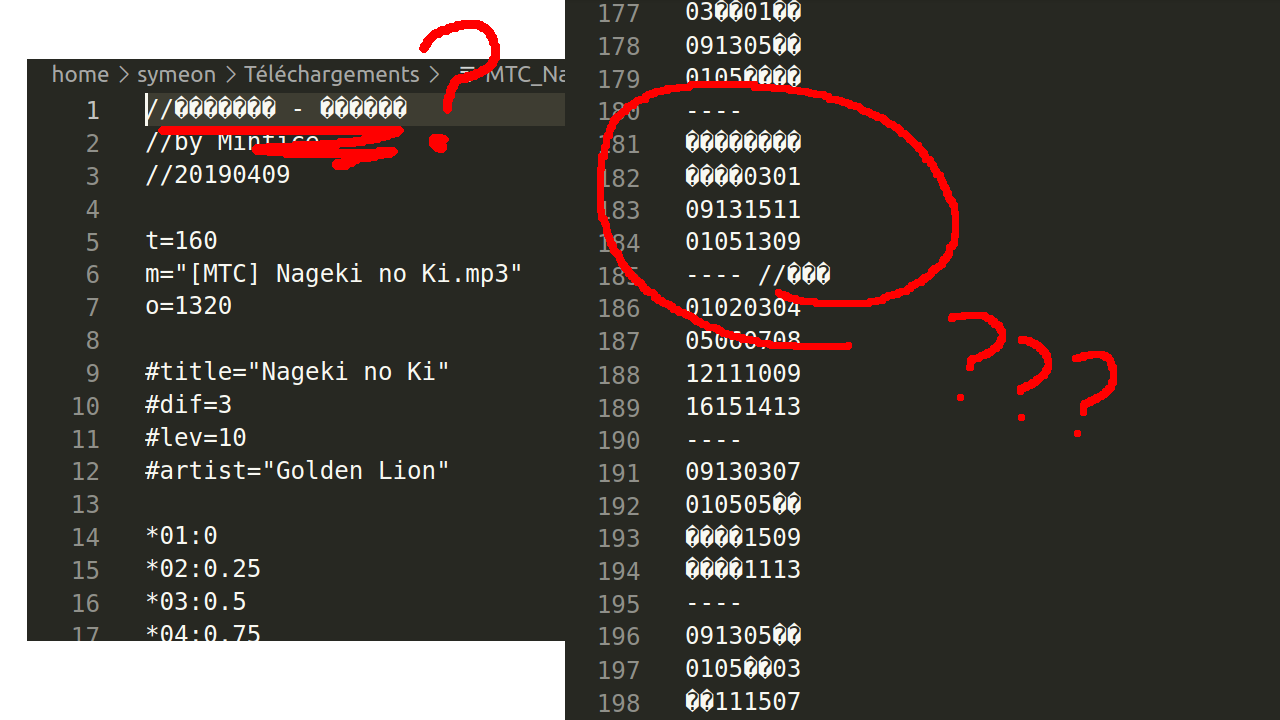
At this early stage of diagnosis, seeing �s displayed does not worry me. Maybe my text editor just couldn't guess the encoding. Let's see what we get when I tell it it's ✌️Shift-JIS✌️ ...
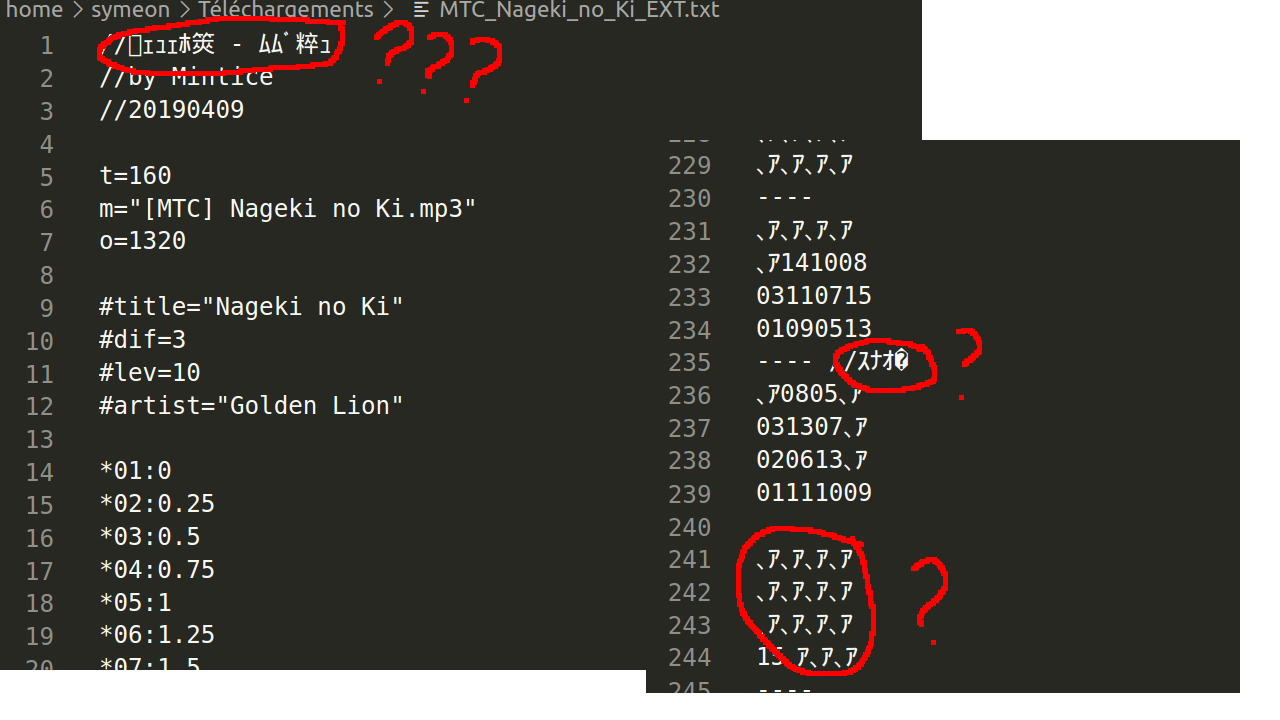
Now this is strange :
- the comment at the top does not look any better
- the chart is full of
、アs : smells like mojibake - worst of all, there are still �s floating around !
If you're unfamiliar with �, it's a common way to show that at this point in the file, the byte sequence could not be understood as text according to the chosen encoding. So here I'm like 99% sure my choice of encoding is wrong.
In reality there was no mystery around the encoding, the person told me upfront this file was using EUC-KR, a Korean encoding.
Knowning this, the file looks fine :
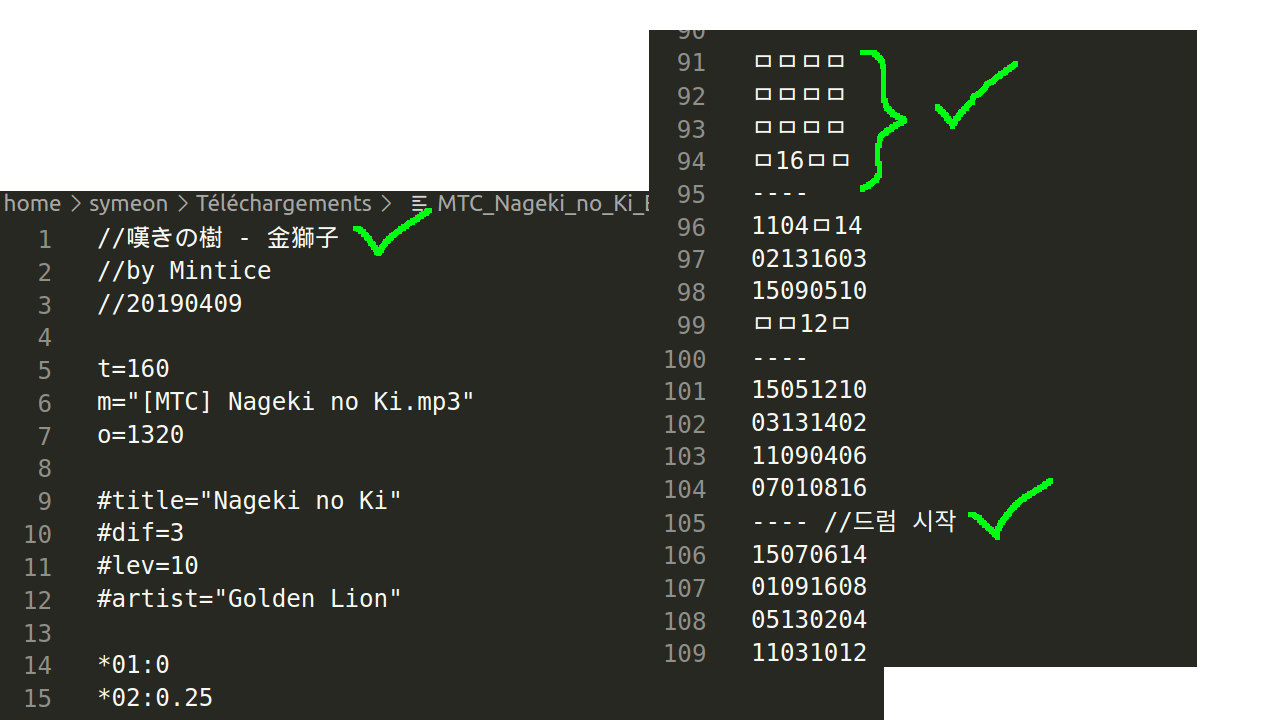
But ...
How on earth does jubeat analyser handle this file correctly ?
The only existing piece of documentation very clearly states that files must use ✌️Shift-JIS✌️ to be understood correctly ...
Whatever, at this point I'm already assessing damage and coming up with a battle plan on how jubeatools should ask the user for the encoding they want me to use for their file. And I'm trying not to think too much about how I'll have to rewrite whole chunks of the code just to correctly pass this new parameter down the chain ...
When all of a sudden !
The person sends a second file over, that also does not work, and in it, I find what should be given the award for best multi-encoding bodge ever ...
The person then explains the original author of this chart tried adding long notes in it.
Quick refresher, in jubeat analyser formats, long notes are written visually, with arrows, so they look kind of what they look like in the actual game :
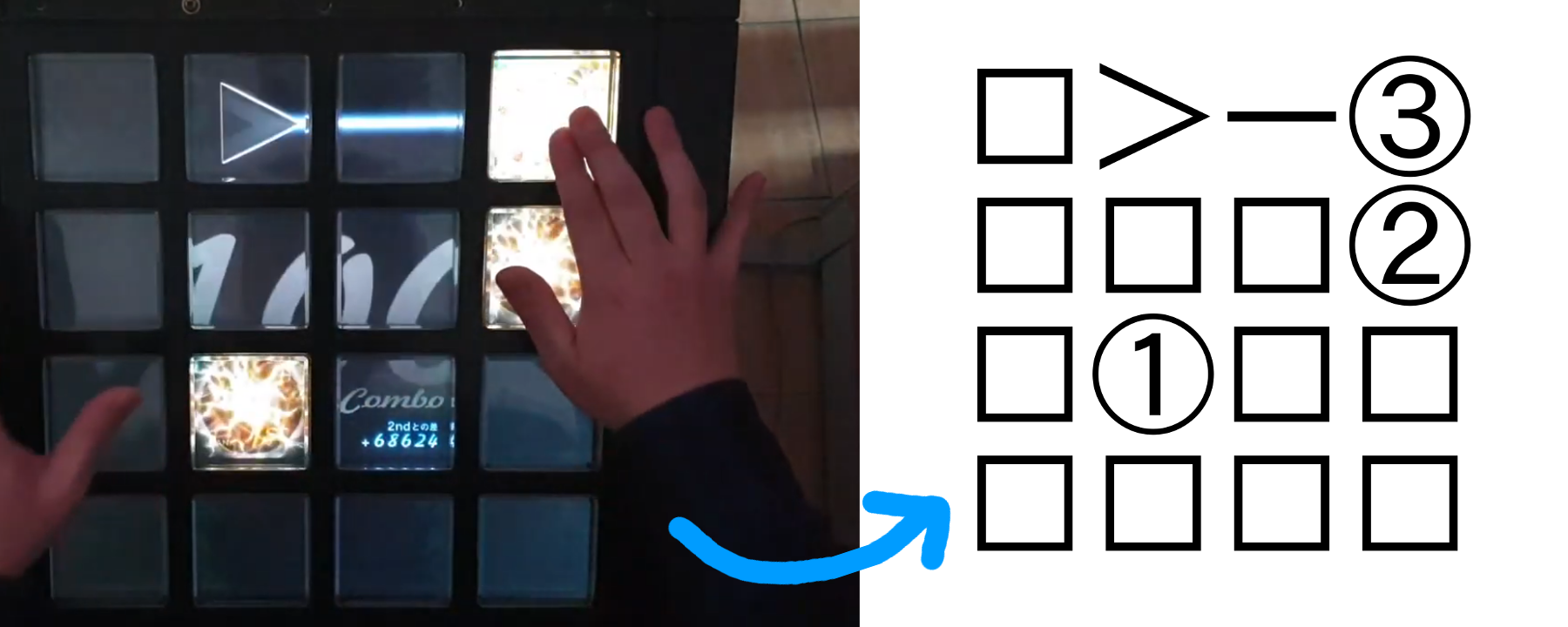
So I open the second file thinking I'll find a bunch of >s and <s and ∨s and ∧s all over, but ... surprise ! When the file is read as EUC-KR ... there's none !
However, a comment at the start indicates which characters are used instead
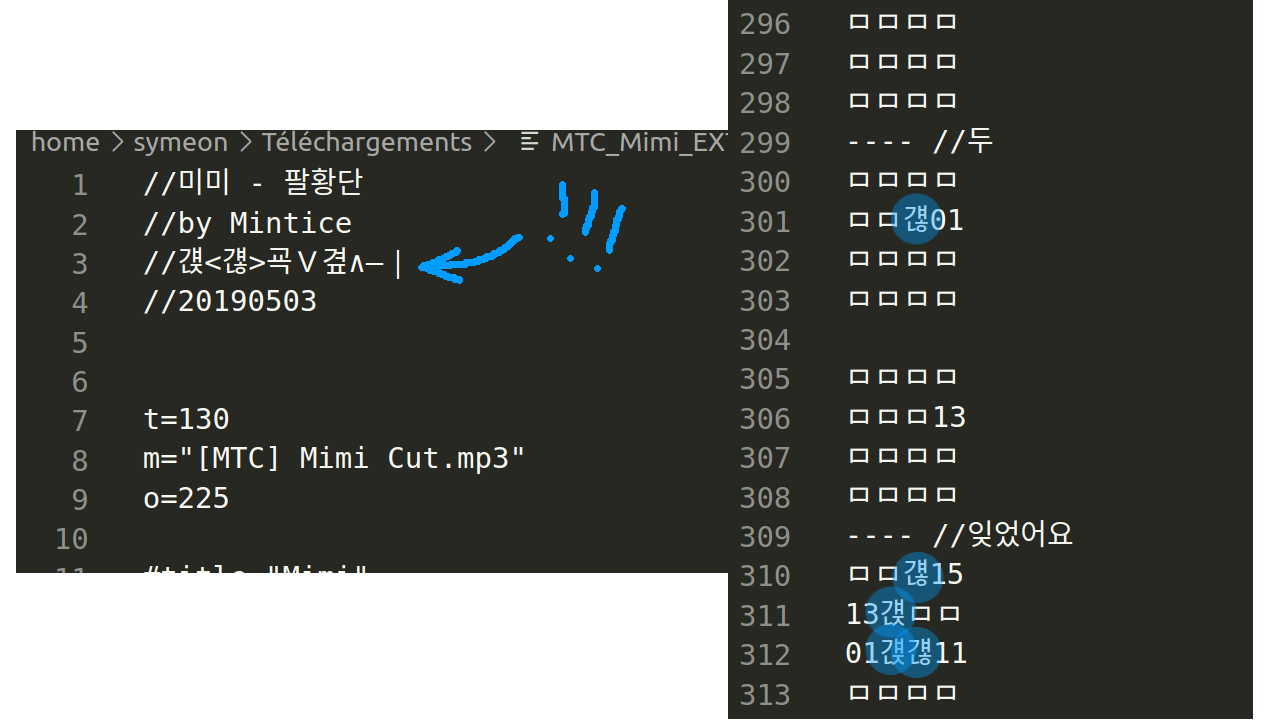
But ... but ...
Why are these specific characters working instead of the arrows in a EUC-KR file ? They look nothing alike ! How does jubeat analyser have any chance of understanding these are supposed to be arrows ?
And then it clicked : actually ... jubeat analyser does not give a damn about encoding, and just handles everything at the byte level, without decoding.
When jubeat analyser's docs say that it expects files to use ✌️Shift-JIS✌️, that should not be understood in the strict sense, which would mean :
The file MUST be completely readable as valid ✌️Shift-JIS✌️
Instead I think what it actually means is :
I don't care about whatever stupid encoding you use, but if I ever ask you to write a specific character in your file, it MUST be written with the same byte sequence it would use in ✌️Shift-JIS✌️
So if we come back to my bug, actually at no point is jubeat analyser trying to guess the file encoding. From the begging it's been handling the file as raw bytes (as is often the case with programming languages that make you believe that bytes==text), and as long as it finds the bytes it wants at the positions it expects, there's no problem.
In this second file, we are actually witnessing some hand-crafted reverse-engineered mojibake, just like grandma used to make.
The file author found by hand which Korean characters would get encoded in EUC-KR the same way as the arrow symbols in ✌️Shift-JIS✌️, in other words the characters that use the same byte sequence.
To show that, let's do a little digital sleight of hand with python :
I take the character "걚" (which, according to the comment in the file is the one used instead of ">")
>>> c = "걚"
I encode it in EUC-KR
>>> c.encode("euc-kr")
b'\xa4\xd4\xa4\xa1\xa4\xc2\xa4\xa6'
We get this byte sequence
A4, D4, A4, A1, A4, C2, A4, A6
Or in decimal :
164, 212, 164, 161, 164, 194, 164, 166
I will now take these bytes and do "just like" what jubeat analyser does, I'm gonna read it as if it were ✌️Shift-JIS✌️
>>> c.encode("euc-kr").decode("shift-jis-2004")
'、ヤ、。、ツ、ヲ'
Err ... wait ... aren't we supposed to get something like ">" here ? wtf ?
Because the fun does not stop there, I've been telling you about EUC-KR all this time, but at this point I figured out the hard way that this file was actually using yet ANOTHER encoding all along. I claim VSCode as the root cause of my fuckup. VSCode is made by our good friends over at Microsoft. And when you ask Microsoft for EUC-KR, behind the scenes, without telling you, they'll actually add in their totally cool and also totally non-standard extension, which python calls "cp949" and not "euc-kr".
We've already seen this kind of problem with ✌️Shift-JIS✌️ : Microsoft imposed its non-standard extensions to some system that already had a name. This means that what Microsoft calls ✌️EUC-KR✌️ is not what Wikipedia calls EUC-KR.
This has the very minor and totally unintentional side effect that 95% of users will now think that Microsoft's proprietary extension is the standard
Anyway, we all love Microsoft, xoxox. Thanks to them, computers are easy to use and fast for everyone !
... So ... as I was saying, I encode it as ✌️EUC-KR✌️ then decode it as ✌️Shift-JIS✌️ and !
>>> c.encode("cp949").decode("shift-jis-2004")
'>'
tadaaaa, the > pops out of the hat !
To sum things up, if someone on a Windows computer configured for Korean writes a text file with "걚" in it, the byte sequence that actually gets written to disk for this character will be the same as the one used for ">" on a Windows computer configured for Japanese.
"Ok great, dude found a way to make jubeat analyser understand "arrow" via a Korean encoding, but why is the file working in the first place when it looks like that when read as ✌️Shift-JIS✌️"
、ア、ア、ア、ア
、ア、ア、ア、ア
、ア、ア、ア、ア
、ア、ア、ア、ア
----
、ア、ア15、ア
、ア13、ア、ア
、ア0511、ア
01090307
----
01、ア、ア07
、ア0903、ア
0513、ア11
、ア、ア、ア15
----
"Isn't it suppoed to look more like that ?"
□□□□
□□□□
□□□□
□□□□
----
□□15□
□13□□
□0511□
01090307
----
01□□07
□0903□
0513□11
□□□15
----
The 、アs don't bother jubeat analyser for another reason :
It is ultra permissive with the characters it expects in the position part
Actually, in the position part of a chart, everything that's not :
- a circled number like ①, ②, ③, ④ (not used by this file)
- a symbol from a previous definition (the
*04:0.75thingies at the begging) - two dashes at the begging of a line (which marks the end of a section)
just gets ignored.
The docs mention this and show how you can use this to add a bit of decoration to your chart, for instance to make it clearer that a square is currently being held because of a long note, like this :
①――< |①---|
□□□□ |----|
□□□□ |----|
□□□□ |----|
■□□□ |----|
□□□□ |----|
□□□□ |----|
□□□□ |----|
①□□□ |①---|
□□□□ |----|
□□□□ |----|
□□□□ |----|
The "■" is not interpreted in any way, it's just ignored.
It's because of this that jubeat analyser deals with this file even when it's full of weird 、アs
Btw these 、アs are here because the chart author used "ㅁ" (U+03141 : HANGUL LETTER MIEUM) as an empty square in their file instead of "□" (U+025A1 : WHITE SQUARE). Once decoded like I've just shown, we get back 、ア
>>> "\u3141".encode("cp949").decode("shift-jis-2004")
'、ア'
It's all weel and good
But how do I deal with this nonsense ? I can't just ignore the wrong bytes in the file, python crashes if I pass in a file that's not fully valid ...
Bad idea : Fall back to ✌️EUC-KR✌️ if ✌️Shift-JIS✌️ fails
This is a bad idea, I can already see another guy coming from 1000 miles away with a file with the same tricks but with a Chinese encoding, and another one with Vietnamese etc etc etc. "Solving" the problem this way would mean I commit to maintaining a list of all the encoding I might wanna try, in which order I should try them blah blah blah
This is going to clutter the code a whole lot when I have to write special cases for each encoding saying "well in Japanese it's these arrow symbols, in Korean these, in Chinese these etc etc etc"
Also this does not solve another problem : sometimes a "text" file isn't even in any particular encoding at all ! That's uncommon but to this day I still remember one file I found that was part ✌️Shift-JIS✌️, part some other Chinese encoding. In this case neither encoding would work for the whole file, yet somehow jubeat analyser deals with it just fine.
Less bad idea : handle everything at the byte level without decoding
This should work a lot better, but it'll require such a HUGE effort. I'd have to redo parts of code in nearly EVERY. FILE. so it's handled properly. But at least we'll be guaranteed my code works just as well as jubeat analyser ! (as in, not very well)
At first I really thought I would have to do this, but then I remembered
GOOD IDEA : just ignore the wrong bytes in the file
I had forgotten, but actually yeah, python can totally just ignore decoding errors when it's reading a file. There are even multiple different ways it can do that, all of which are documented
I ended up using surrogateescape so I can get back the original bytes, even if they are invalid as ✌️Shift-JIS✌️. I need this because there's ONE piece of the code that actually has to use a trick based on the length of the text in bytes (encoded) to be able to correctly read the file. So I need to keep to original bytes for this, even if they do not represent valid character in ✌️Shift-JIS✌️.
Solving the problem this way has the huge advantage of being as non-disruptive as possible : the existing code can continue manipulating str objects throughout, and all I have to do is add in errors="surrogateescape" to the few input and output points.
For once, all is well that ends well
I add in a test case with both files, it works, new patch released on the same day.
You can now throw even uglier files at jubeatools 1.1.3, it should just deal with it !
Thanks to Nomlas and Mintice for reporting this bug !