No matter the abstraction level you work at on the tech stack, there's often a feeling the people lower than you have it worse and vice versa. For some definition of "the tech stack", file format people are at the very bottom, and hence get to deal with the ugliest stuff. Or at least that's what I think now that I wrote a parser+dumper for an (almost) legacy Japanese file format.
You're probably wondering how I got into this situation
I love rhythm games, been a big fan since ... well uh basically forever. For quite a while I got really really into jubeat in particular.
(that's me playing btw)
In this game the buttons make up a 4×4 grid. They're transparent and go over the screen, this way the screen can show you which square you need to hit next with a small animation. And as always with rhythm games everything happens in sync with the beat of the music you've chosen. It's very beginner-friendly while still offering a decent challenge at the higher levels.
I love jubeat. In fact I love it so much I wanted to create my own songs for it. Unfortunately, unlike DDR with Stepmania, the jubeat simulator scene never really took off for some reason. Simulators do exist, like jubeat analyser or jubeat analyser append, but for some reason there is close to zero content for them.
I didn't really know why that was, but what struck me when I first tried creating custom songs was that both simulators use a custom text file format to store charts and there's no usable GUI editor for it like Stepmania has.
Want to create a custom song ? Text editor. Not the smoothest experience ever. I found that so discouraging that I decided I had to improve the situation myself.
So, because of reasons, I was now going to write my very first parser for an obscure file format, and oh boy I was not prepared.
Meet memo
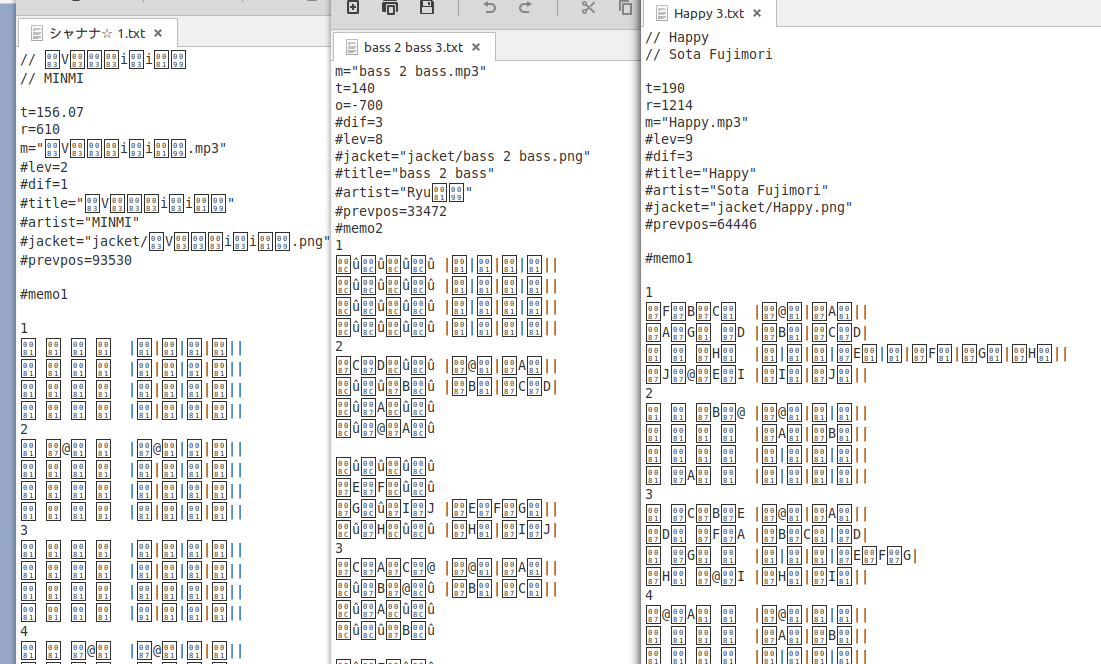
Or at least what most people opening it up for the first time will see, this is just mojibake by the way. Most text editors won't automatically notice that it's actually ✌️Shift-JIS✌️ (notice the air quotes).
If I have learned one thing from parsing it, It's the meaning of the word endemic.
This format :
- was created by Japanese people for Japan
- has its "reference" implementation written in HotSoup (a Japanese BASIC variant)
- uses Japanese text encoding (which is a whole other can of worms)
{kind=link}
However, once properly decoded, it's not that ugly, in fact quite the opposite. It uses a visual layout for note position and timing :
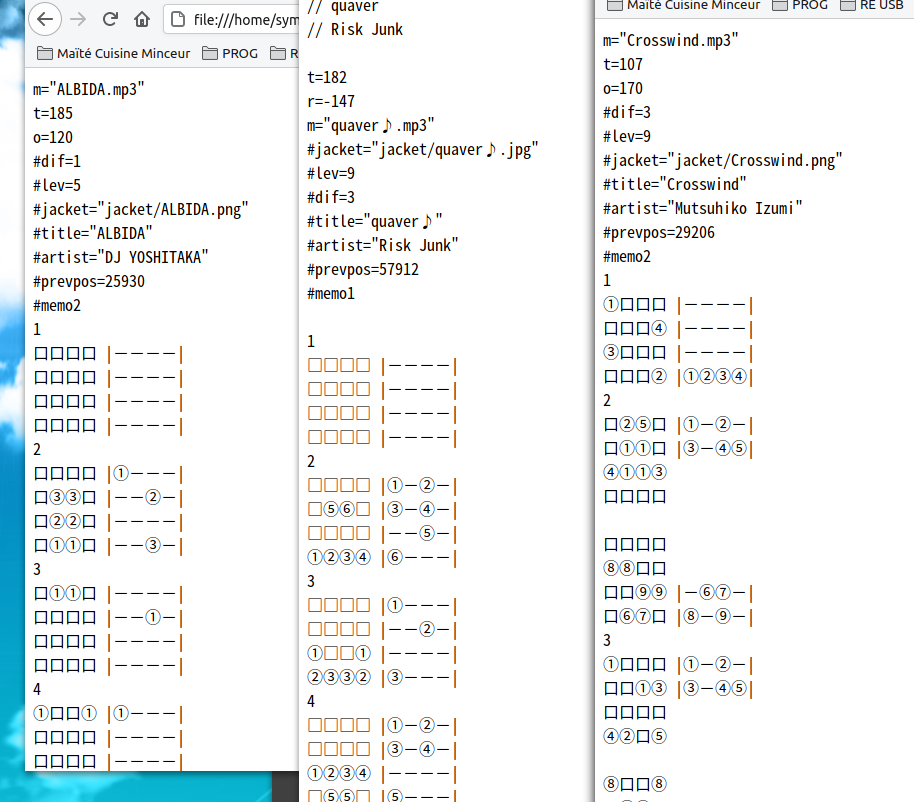
You can see there's a bit of metadata at the top, and then a sequence of numbered blocks begins. For each block, the left-hand part is for the position of notes, while the right-hand part is for the timing of notes.
I pieced together after reading the only existing form of documentation about the format (which surprisingly exists at all) that it was actually conceived so you could rip the text from websites such as cosmos memo, throw a few tags at the top, and with minimal tweaking, end up with a text file jubeat analyser could understand. At some point, "memo" websites were the only place you could get the note patterns for each song in the game without going to an arcade. Hardcore players most likely used it as training material. The maker of jubeat analyser probably just decided to go along and create a "proper" format from the visual and textual layout these websites chose.
As is often the case with "visual" computer stuff (I'm mostly thinking drag & drop / node-based programming for instance), what seems like a great idea at first will later fall somewhere between "very limiting" and "batshit insane" when someone actually has to make it work.
Actually making it work
"OK, let's see, I'll just fire up Python and ..."
Python 3.9.0 (default, Oct 25 2020, 19:44:11)
[GCC 7.5.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> open("concon 3.txt").readlines()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/symeon/.pyenv/versions/3.9.0/lib/python3.9/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8c in position 137: invalid start byte
>>>
"... oh ... ok, yeah, right ... ✌️Shift-JIS✌️, let's try that again."
Fortunately Sam & Max properly warned me that encodings exist and are complicated and that thankfully Python is one of the few languages with non-shitty support for them out of the box (a least in 3.0 and up, for the older ones in here with war flashbacks about 2.x)
"So, what if I try again with the right codec this time ..."
>>> open("concon 3.txt", encoding="shift-jis").readlines()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'shift_jis' codec can't decode byte 0x87 in position 224: illegal multibyte sequence
>>>
"OK WHAT NOW ? I THOUGHT PYTHON SUPPORTED ENCODINGS PROPERLY ?"
Well, you see, actually, when Japanese people mention ✌️Shift-JIS✌️ in their docs, what they really mean almost certainly contains some non-standard extension. Which unsurprisingly often happens to correspond to whatever bs legacy thing Windows does by default when configured for Japanese audiences.
Again : Japanese encoding. can of worms. do NOT open.
After looking at the actual bytes used to encode the circled numbers and much, MUCH research. I found a website showing a character table that matches. Turns out Python calls this encoding shift-jis-2004 instead of just shift-jis. I'm still in awe at the fact you can get Firefox to properly display these files just by telling it they use "Japanese" encoding, without further detail.
"Ok now I have the "raw" text, moving on ... a few easily regexable metadata, then 4x4 blocs on the left with 4 beats each 4 ticks long on the right, each block separated by either blank lines or a number. How hard can that be ? ..."
"... wait, wtf are those 口 symbols ? why isn't it □ U+25A1 WHITE SQUARE ?"
This is actually the kanji for "mouth", it just happens to look a lot like a white square, especially on low-res monitors. Memo files use both symbols almost interchangeably.
"Ok well, whatever, I can code that in, alright, that's easy ..."
"... Waiiiit a minute, what's this ?"
57
⑩口口⑨ |①--②③④|
②③④⑤ |⑤-⑥-|
⑧⑩口① |⑦-⑧-|
口口⑦⑥ |⑨-⑩-|
See the first bar ? It's not 4 but 6 characters long. This does not mean it lasts longer but rather that the same amount of time a "normal" bar would last is now divided into 6 "beats" instead of 4. It's just that 95% of notes will gladly fit inside a 4 "beats", 4 bars measure. But that's not always the case, as Adam Neely warned me. So memo allows for flexible bar subdivision like that. It can change at any point, which means the last snippet is equivalent to
57
⑩口口⑨ |①-----②-③-④-|
②③④⑤ |⑤⑥|
⑧⑩口① |⑦--⑧--|
口口⑦⑥ |⑨---⑩---|
It's just easier to read when it's written the other way.
"okay ... fine ... I guess I'll have to whip out the weird numbers for that. Still no big deal ..."
"... but wait, what's this now ?"
4
□③①□ |①-②-|
□②④□ |③④⑤-|
□□□□
□⑤□□
□□□□
⑥□⑨⑥
□□□□ |⑥-⑦-|
□□⑦⑧ |⑧-⑨-|
Ahh well see, in this block (notice the second part isn't numbered with a "5", so it's all one "block"), notes ④ and ⑨ are in the same position, but happen far enough in time from one another to not visually intersect during gameplay, so to ease reading, the block is split into two 2-beat sub-blocks.
Here's the same block again, but I've only kept ④ and ⑨ :
4
□□□□ |----|
□□④□ |-④--|
□□□□
□□□□
□□□□
□□⑨□
□□□□ |----|
□□□□ |--⑨-|
Notice how they are both on the same square, but are a few beats appart.
Subdivisions like this can happen unannouced at any point, and my early code reaaally did not like that idea. This is the point I got personally stuck at for a looong time when I had just learned Python and this was basically my first personnal programming project.
It's now years later, and I've finally gone past this point. Is that all you got memo ?
Of course not.
①⑩⑩④ |(135)①②③④|
□⑤②□ |⑤⑥⑦⑧|
⑦⑨⑨⑦ |-⑨-⑩|
⑧③⑥⑧ |(540)-|
①⑩⑬④ |(135)①②③④|
⑭⑤②⑭ |⑤⑥⑦⑧|
⑦⑫⑨⑦ |⑨⑩⑪⑫|
⑧③⑥⑪ |(270)⑬⑭|
①⑩⑩④ |(135)①②③④|
□⑤②□ |⑤⑥⑦⑧|
⑦⑨⑨⑦ |-⑨-⑩|
⑧③⑥⑧ |(540)-|
See the numbers in parentheses on the timing part ? These are BPM changes, they can happen at any point and are not actually related to notes, they just indicate the BPM of the song changes at this point. IF you were clever enough to not store your note timings as seconds but instead as beat fractions, this won't cause much trouble. Big if ...
If you thought all of this was already complicated, don't worry :
- you're not alone
- there's more
Jubeat introduced long notes at some point, meaning that some notes now require you to hit and hold the button for a given amount of time. It's an interesting gameplay element, harder songs use them to force you to hit harder patterns with your free hand while your other hand is busy holding the long note. Take a quick look at how long notes are displayed in the game :
There's a tail with a triangle tip that retracts towards the held button. When the tail is fully retracted, the note ends. kinda cute.
Now can you guess how long notes got bodged in ?
That's right, visually again.

Oh dear.
We now have to correctly parse absolute masterpieces such as this quadruple block
13
口口口② |①-②-|
口口口|
①口口∧
口口口②
③―<③
口口口口 |--③-|
口口口口
口口口口
④口口口
∨口口口
|口口口 |--④-|
④口口口
口口口口
口⑤⑤口
口口口口
⑤口口口 |--⑤-|
The tail lines are absolutely optional btw, it all works if you just put the triangle symbols.
What even are these triangle symbols anyway ?
The docs mentions you can use
'>' # U+0FF1E : FULLWIDTH GREATER-THAN SIGN
'∨' # U+0FF36 : FULLWIDTH LATIN CAPITAL LETTER V
'<' # U+0FF1C : FULLWIDTH LESS-THAN SIGN
'∧' # U+02227 : LOGICAL AND
But really a wild memo file observed in its natural habitat might as well use any of these :
LONG_ARROW_RIGHT = {
">", # U+003E : GREATER-THAN SIGN
">", # U+FF1E : FULLWIDTH GREATER-THAN SIGN
}
LONG_ARROW_LEFT = {
"<", # U+003C : LESS-THAN SIGN
"<", # U+FF1C : FULLWIDTH LESS-THAN SIGN
}
LONG_ARROW_DOWN = {
"V", # U+0056 : LATIN CAPITAL LETTER V
"v", # U+0076 : LATIN SMALL LETTER V
"Ⅴ", # U+2164 : ROMAN NUMERAL FIVE
"ⅴ", # U+2174 : SMALL ROMAN NUMERAL FIVE
"∨", # U+2228 : LOGICAL OR
"∨", # U+FF36 : FULLWIDTH LATIN CAPITAL LETTER V
"∨", # U+FF56 : FULLWIDTH LATIN SMALL LETTER V
}
LONG_ARROW_UP = {
"^", # U+005E : CIRCUMFLEX ACCENT
"∧", # U+2227 : LOGICAL AND
}
The end of a long note is written as another normal note that just happens later on the same square as the one with the tail, like that :
①――< |①---|
□□□□ |----|
□□□□
□□□□
②□□□
□□□□
□□□□ |----|
□□□□ |--②-|
This way the long note starts on ① and lasts up to ②
Also notice, when the long note is vertical, that the character used to draw its "tail" is the exact same as the timing portion delimiter (U+FF5C FULLWIDTH VERTICAL LINE), hope your parser deals with that somehow.
Oh and by the way, we now have AMBIGUOUS CASES
①①<< |①---|
□□□□ |----|
□□□□ |----|
□□□□ |----|
Take a good look at this.
Is it :
- two
①―<s ? - a
①――<and a①<?
We don't know !
The only thing we know for sure is that you now have to rewrite your parser from scratch !
At this point I believe most of you are already trying to come up with an excuse to dismiss this case as unreasonable. And that's ok, this whole thing is self-inflicted anyway, you may as well go to sleep each night feeling perfectly at peace with the fact your code works "only" with 99% of files.
But for the rest of you still willing to try, let's keep digging ...
Think you came up with a quick way to sort that first case out ? Try this one !
□□□□ |①---|
□①□□ |----|
>①①< |----|
□∧□□ |----|
The bottom left ① has 3 arrows pointing towards it !
Oh, think I didn't see you there Mr. Smarty Pants, trying to smugle in a CSP Solver ?
How about this one then ?
□∨□□ |①---|
□①□□ |----|
□□□□ |----|
>①□① |----|
Whatever code you will come up with should find three solutions :
□∨□□ □□□□ □□□□
□●□□ + □□□□ + □□□□
□□□□ □□□□ □□□□
□□□□ >●□□ □□□●
or
□∨□□ □□□□ □□□□
□●□□ + □□□□ + □□□□
□□□□ □□□□ □□□□
□□□□ >――● □●□□
or
□∨□□ □□□□ □□□□
□|□□ + □□□□ + □●□□
□|□□ □□□□ □□□□
□●□□ >――● □□□□
At this point you have a choice, you can either refuse the temptation to guess, and bother your human with a question, or come up with a smart sounding way of explaining you're just guessing (that usually involves the word "heuristic"). Guessing seems resonable here though : realistically you know you should only keep the first solution, there's no way a human would have written the other two this way.
So now not only do you need some form of back-tracking alg for the harder cases, but you also need to come up with some ✨heuristic✨ to try and guess what the human meant.
For the algorithm, now is the time to flex whatever you remember from your CS courses, if you are into this sort of thing. I personnaly decided I had nothing to prove here and went with an off the shelf CSP solver, namely python-constraint (amazing API by the way, love it when it's that simple !)
Modelling this as a CSP is surprisingly neat.
- Arrows are going to be our variables.
- The domain (possibles values) of a given arrow will be all the circled numbers in its direction
- The only constraint will be that every arrow must "choose" a different circle
In python this becomes
import constraint
problem = constraint.Problem()
for arrow_pos, note_candidates in arrow_to_note_candidates.items():
problem.addVariable(arrow_pos, list(note_candidates))
problem.addConstraint(constraint.AllDifferentConstraint())
solutions = problem.getSolutions()
I love the solutions = problem.getSolutions() line.
The heuristic also wasn't easy to come up with, my first idea was to minimize the total length of long note "tails", but that would mean that this in this case :
①①<< |①---|
□□□□ |----|
□□□□ |----|
□□□□ |----|
both solutions
●――< □●<□ ●―<□ □●―<
□□□□ + □□□□ or □□□□ + □□□□
□□□□ □□□□ □□□□ □□□□
□□□□ □□□□ □□□□ □□□□
would "rank" equally and I really wanted the second one to win (since the docs specifically say the reference parser interprets it this way).
What I ended up using was a lexicographic sort on (#3s, #2s, #1s) tuples (number of tails with length 3, 2, 1), it's simple to code but I'd have a hard time intuitively describing how it behaves ...
Anyway, do you realize we are seriously talking about CSP Solvers and heuristics just to parse a text format ?
BUT THE FUN DOESN'T STOP THERE
What if you want to make it clearer that some circled number is used for the end of a long note ? Well you can ! The docs specify that if you just throw in a #circlefree=1 line in the metadata, you can now write this :
∨∨∨∨ |①---|
□□□□ |②---|
①②③④ |③---|
□□□□ |④---|
□□□□
□□□□
234□
□□□□
That's right, these 234 are Full-Width characters. The first three long notes now end at the time described by ②, ③ and ④ in the timing part.
Now take a deep breath
Pause
Ponder
What comes after 9 ?
∨□□□ |⑨---|
□□□□ |----|
⑨□□□
□□□□
□□□□
□□□□
10□□□ |----|
□□□□ |--⑩-|
Another fundamental assumption has now been proven wrong, please remain calm
yeah ... this is "legal" ...
And yes that's "10" as two characters.
If my font shenanigans worked, you should see this "10" looks as wide as a single white square. This replicates how older Japanese computers (and of course Windows) would render it in most situations. Obvisouly that's just the visual representation though, in reality the position part of this line is now 5 characters longs. Which means your parser now has to somehow deal with the fact the position part of a line can be anywhere between 4 and 8 characters long ...
How do you handle THAT ? If you're a real Unicode nerd you might be aware of Unicode Character Properties, and especially East Asian Width. That might work somehow, but what if a single narrow character slips in at any point ? How about the multiple variants of long note arrows ? Surely some of them get usually displayed as fullwidth but aren't conscidered fullwidth by the standard ?
Here, I think trying to solve this in unicode land is too much trouble. If you accept the fact that the original files are in ✌️Shift-JIS✌️ and that all this unicode stuff is just some intermediate representation we use to deal with the text in transit, the docs give a hacky but much simpler solution :
Slap a #bpp=1 or 2 (bytes per panel) tag at the top, and slice the ✌️Shift-JIS✌️ encoded version every 1 or 2 bytes accordingly.
Yup, this works because here somehow the fullwidth characters we are interested in all encode to 2 bytes, while the halfwidth ones only encode to 1 byte.
And that is going to be our final bodge for the day.
Thanks for reading !
If that seemed bad, remember this was only a guided tour of some of the problems, and I only wrote about a few parts of the solution.
The moral of the story is I never want to have to touch that format again, and also I'm working on a whole ecosystem around a new format that's just a JSON file with some defined schema (yeah I know). Want to use your memo files with my new shiny tools ? I provide a converter, but that is it. This way the converter is the only piece of code that ever has to deal with memo files, and I don't technically lock people in.
If you wanna see (a lot) more code, you can checkout the converter here. I think it's pretty close to being the most complete re-implementation of the format, but there are still a few things the documentation talks about that I did not bother adding in, like tail-less long notes (not a thing in original arcade jubeat, implementation further destroys assumptions about the position part of memo files), or this weird notation that's used by jubeat analyser to color groups of notes in a specific way (which has absolutely no effect on their position or timing).
Since jubeatools is meant to be two-way, I also wrote a dumper for memo files. Having an encoder / decoder pair like this makes it really easy to write property-based tests using hypothesis. Hypothesis takes some effort, getting used to its concepts and actually writing the test code to generate memo files was not exactly easy. But once it's done you really get to enjoy how much hypothesis ROCKS. It finds bugs instantaneously. At one point I thought it was getting too slow, so slow I had to shut it off after a few minutes of seemingly doing nothing. Actually it had just found some input that triggered an infinite loop in my code 😅. Its major downside is that it's restricted to a few specific test patterns where it really shines, like the aforementioned encode / decode. But if what you're coding happens to match one, try it. I've never been this confident my code works, this is really something else.
Bonus round !
There are actually 4 different formats jubeat analyser is compatible with, I only presented the most recent one, #memo2, there's also #memo1, #memo, and the unnamed mono-column format. They all differ in subtle ways that make them (especially #memo and #memo1) reaaaally weird to parse+dump. Maybe for another blog post !